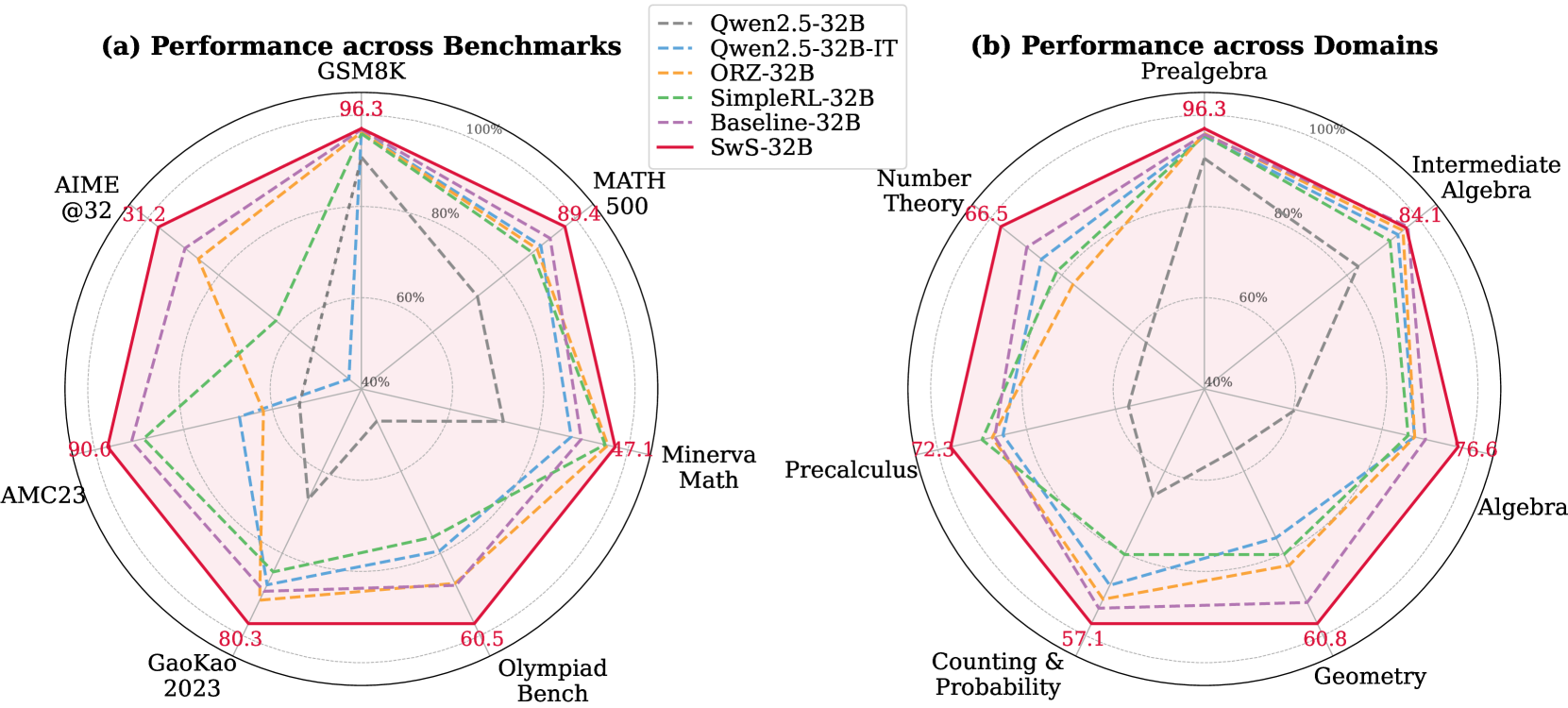
## Radar Charts: Performance Comparison of Language Models
### Overview
The image presents two radar charts comparing the performance of several language models across different benchmarks and domains. Chart (a) shows performance across benchmarks (GSM8K, AIME@32, AMC23, GaoKao 2023, Olympiad Bench, MATH 500, Minerva Math, Precalculus), while chart (b) displays performance across mathematical domains (Prealgebra, Number Theory, Counting & Probability, Geometry, Algebra, Intermediate Algebra). The models being compared are Qwen2.5-32B, Qwen2.5-32B-IT, ORZ-32B, SimpleRL-32B, Baseline-32B, and SwS-32B.
### Components/Axes
Both charts share the following components:
* **Radial Axes:** Representing different benchmarks/domains. The axes are labeled with the benchmark/domain names.
* **Concentric Circles:** Representing performance levels, ranging from 0% to 100%. The circles are marked at 20% intervals (20%, 40%, 60%, 80%, 100%).
* **Lines:** Each line represents the performance of a specific language model.
* **Legend:** Located in the top-left corner of each chart, identifying each line with a specific color and model name.
**Chart (a) - Performance across Benchmarks:**
* Benchmarks: GSM8K, AIME@32, AMC23, GaoKao 2023, Olympiad Bench, MATH 500, Minerva Math, Precalculus.
**Chart (b) - Performance across Domains:**
* Domains: Prealgebra, Number Theory, Counting & Probability, Geometry, Algebra, Intermediate Algebra.
### Detailed Analysis or Content Details
**Chart (a) - Performance across Benchmarks:**
* **Qwen2.5-32B (Purple):** Shows generally high performance, peaking at approximately 96.3% on GSM8K, and maintaining relatively high scores across all benchmarks. The line is mostly above 80% except for Minerva Math (around 47.1%) and Precalculus (around 72.3%).
* **Qwen2.5-32B-IT (Orange):** Similar to Qwen2.5-32B, with a peak of around 96.3% on GSM8K. It shows slightly lower performance on AIME@32 (around 31.2%) and AMC23 (around 90.0%).
* **ORZ-32B (Green):** Demonstrates strong performance, peaking at approximately 96.3% on GSM8K. It shows a dip on Minerva Math (around 47.1%).
* **SimpleRL-32B (Blue):** Generally lower performance than the other models, with a peak of around 80.3% on GaoKao 2023. It shows the lowest performance on Minerva Math (around 31.2%).
* **Baseline-32B (Red):** Moderate performance, peaking at around 89.4% on MATH 500. It shows lower performance on AIME@32 (around 31.2%).
* **SwS-32B (Teal):** Performance is variable, peaking at around 80.3% on GaoKao 2023. It shows a low score on Minerva Math (around 47.1%).
**Chart (b) - Performance across Domains:**
* **Qwen2.5-32B (Purple):** Highest performance, peaking at 96.3% on Prealgebra. Maintains high scores across most domains, with a slight dip to around 76.6% on Algebra.
* **Qwen2.5-32B-IT (Orange):** Similar to Qwen2.5-32B, peaking at 96.3% on Prealgebra.
* **ORZ-32B (Green):** Strong performance, peaking at 96.3% on Prealgebra.
* **SimpleRL-32B (Blue):** Lower performance, peaking at 84.1% on Intermediate Algebra.
* **Baseline-32B (Red):** Moderate performance, peaking at 84.1% on Intermediate Algebra.
* **SwS-32B (Teal):** Variable performance, peaking at 84.1% on Intermediate Algebra.
### Key Observations
* **Qwen2.5-32B and Qwen2.5-32B-IT consistently outperform other models** across most benchmarks and domains.
* **SimpleRL-32B generally exhibits the lowest performance.**
* **Minerva Math consistently presents a challenge** for most models, resulting in lower scores in Chart (a).
* **Intermediate Algebra is a strong suit** for several models in Chart (b).
* The shapes of the radar charts are similar for Qwen2.5-32B, Qwen2.5-32B-IT, and ORZ-32B, indicating similar performance profiles.
### Interpretation
The data suggests that Qwen2.5-32B and its IT variant are the most capable language models among those tested, demonstrating superior performance across a wide range of benchmarks and mathematical domains. The consistent underperformance of SimpleRL-32B indicates potential limitations in its architecture or training data. The lower scores on Minerva Math suggest that this benchmark presents a unique challenge, potentially requiring specialized knowledge or reasoning abilities. The high scores on Intermediate Algebra for several models suggest a strong foundation in fundamental algebraic concepts.
The radar chart format effectively visualizes the relative strengths and weaknesses of each model across different tasks. The area enclosed by each line represents the overall performance of the model, with larger areas indicating better overall performance. The deviations from the circular shape highlight specific areas where a model excels or struggles. The charts allow for a quick and intuitive comparison of model capabilities, facilitating informed decision-making in selecting the most appropriate model for a given task.