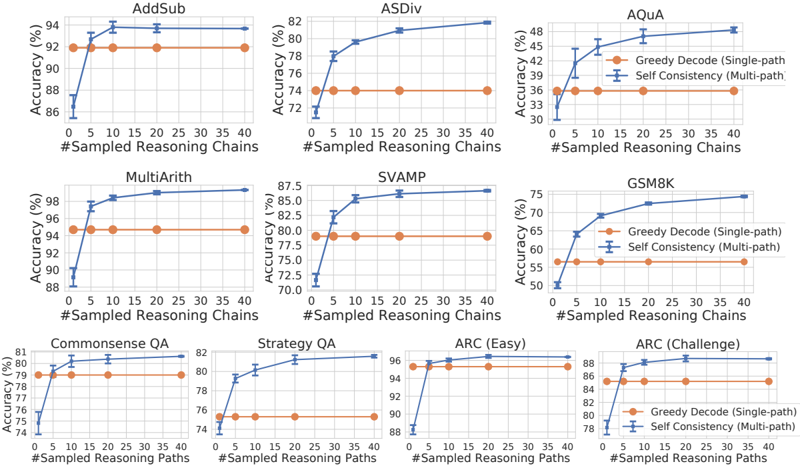
\n
## Charts: Accuracy vs. Sampled Reasoning Chains
### Overview
The image presents a series of nine line charts, each depicting the relationship between "Accuracy (%)" and "#Sampled Reasoning Chains". Each chart represents a different benchmark dataset used for evaluating language model performance. Two data series are plotted on each chart: "Greedy Decode (Single-path)" and "Self Consistency (Multi-path)". The charts aim to demonstrate how increasing the number of sampled reasoning chains affects the accuracy of these two decoding methods across various tasks.
### Components/Axes
* **X-axis:** "#Sampled Reasoning Chains" - Ranges from 0 to 40, with markers at 0, 5, 10, 15, 20, 25, 30, 35, and 40.
* **Y-axis:** "Accuracy (%)" - Ranges from approximately 70% to 98%, varying slightly between charts.
* **Data Series:**
* "Greedy Decode (Single-path)" - Represented by a yellow line with circular markers.
* "Self Consistency (Multi-path)" - Represented by a blue line with triangular markers.
* **Chart Titles (Datasets):** AddSub, ASDiv, AQUA, MultiArith, SVAMP, GSM8, Commonsense QA, Strategy QA, ARC (Easy), ARC (Challenge).
* **Legend:** Located in the top-right corner of the AQUA chart, and is consistent across all charts.
### Detailed Analysis or Content Details
Here's a breakdown of each chart, including approximate data points. Note that due to the image resolution, values are estimated.
1. **AddSub:**
* Greedy Decode: Starts at ~91.5%, increases to ~92.5% at 10 chains, then plateaus around ~92.5%.
* Self Consistency: Starts at ~87%, increases to ~92% at 10 chains, then plateaus around ~92%.
2. **ASDiv:**
* Greedy Decode: Starts at ~75%, increases steadily to ~81% at 40 chains.
* Self Consistency: Starts at ~76%, increases rapidly to ~82% at 20 chains, then plateaus.
3. **AQUA:**
* Greedy Decode: Starts at ~32%, increases to ~36% at 10 chains, then plateaus.
* Self Consistency: Starts at ~30%, increases to ~46% at 40 chains.
4. **MultiArith:**
* Greedy Decode: Starts at ~96%, increases to ~97% at 10 chains, then plateaus.
* Self Consistency: Starts at ~90%, increases to ~98% at 40 chains.
5. **SVAMP:**
* Greedy Decode: Starts at ~83%, increases to ~85% at 20 chains, then plateaus.
* Self Consistency: Starts at ~72%, increases to ~86% at 40 chains.
6. **GSM8:**
* Greedy Decode: Starts at ~52%, increases rapidly to ~72% at 20 chains, then plateaus.
* Self Consistency: Starts at ~50%, increases rapidly to ~75% at 40 chains.
7. **Commonsense QA:**
* Greedy Decode: Starts at ~78%, increases to ~80% at 20 chains, then plateaus.
* Self Consistency: Starts at ~77%, increases to ~81% at 40 chains.
8. **Strategy QA:**
* Greedy Decode: Starts at ~76%, increases to ~80% at 20 chains, then plateaus.
* Self Consistency: Starts at ~74%, increases to ~82% at 40 chains.
9. **ARC (Easy):**
* Greedy Decode: Starts at ~92%, increases to ~94% at 10 chains, then plateaus.
* Self Consistency: Starts at ~90%, increases to ~96% at 40 chains.
10. **ARC (Challenge):**
* Greedy Decode: Starts at ~80%, increases to ~84% at 20 chains, then plateaus.
* Self Consistency: Starts at ~78%, increases to ~86% at 40 chains.
### Key Observations
* **Self Consistency generally outperforms Greedy Decode:** Across most datasets, the "Self Consistency" method achieves higher accuracy, especially as the number of sampled reasoning chains increases.
* **Diminishing Returns:** The accuracy gains from increasing the number of reasoning chains tend to diminish beyond a certain point (around 20-30 chains) for most datasets.
* **Dataset Sensitivity:** The impact of sampled reasoning chains varies significantly depending on the dataset. Some datasets (e.g., AQUA, GSM8, SVAMP) show substantial improvements with more chains, while others (e.g., AddSub, MultiArith) show minimal gains.
* **AQUA is the lowest performing dataset:** The accuracy scores for both methods are significantly lower on the AQUA dataset compared to others.
### Interpretation
The data suggests that employing a "Self Consistency" decoding strategy, which leverages multiple reasoning paths, generally leads to improved accuracy in language model performance across a range of mathematical and reasoning tasks. The benefit of this approach is particularly pronounced in more complex datasets like AQUA, GSM8, and SVAMP, where the model needs to perform more intricate reasoning steps.
The diminishing returns observed with increasing reasoning chains indicate a trade-off between accuracy and computational cost. While more chains can initially improve performance, the gains eventually plateau, suggesting that there's a point where the added computational effort doesn't yield significant improvements.
The dataset sensitivity highlights the importance of tailoring decoding strategies to the specific characteristics of the task. Some tasks may be more amenable to multi-path reasoning than others. The low performance on AQUA suggests that this dataset presents unique challenges for the models being evaluated, potentially requiring specialized techniques or architectures.
The charts provide valuable insights into the effectiveness of different decoding strategies and the impact of reasoning chain sampling on language model performance. This information can be used to optimize model configurations and improve the accuracy of language models on various reasoning tasks. The consistent outperformance of Self Consistency suggests it is a robust strategy for improving performance, but the diminishing returns and dataset sensitivity require careful consideration when applying it in practice.