TECHNICAL ASSET FINGERPRINT
d00f86724d9e6a0f26dde399
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
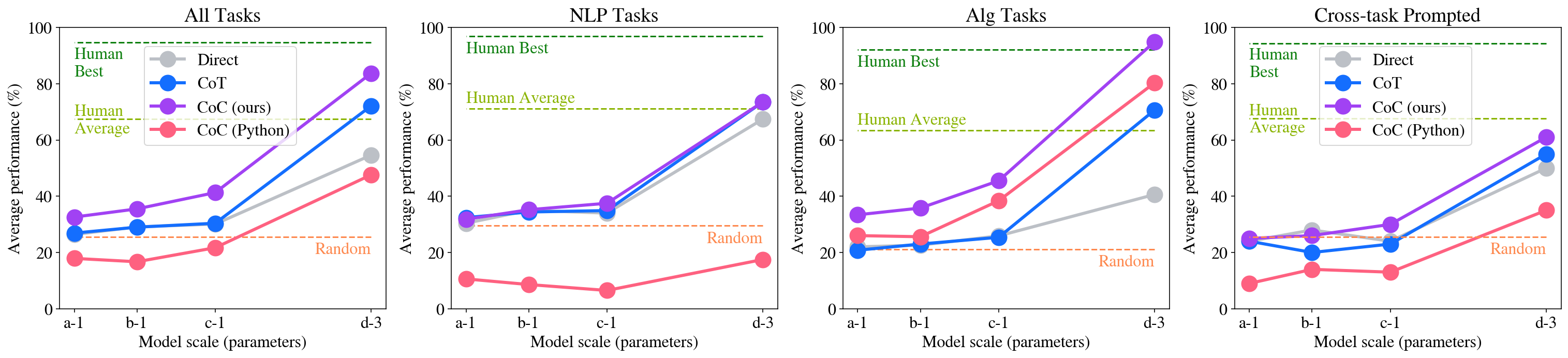
## Line Charts: Performance vs. Model Scale Across Task Categories
### Overview
The image contains four separate line charts arranged horizontally. Each chart plots the "Average performance (%)" of different AI prompting methods against increasing "Model scale (parameters)". The charts are categorized by task type: "All Tasks", "NLP Tasks", "Alg Tasks", and "Cross-task Prompted". Each chart includes four data series representing different prompting strategies and three horizontal reference lines for human and random performance benchmarks.
### Components/Axes
* **Chart Titles (Top Center):** "All Tasks", "NLP Tasks", "Alg Tasks", "Cross-task Prompted".
* **Y-Axis (Left Side):** Labeled "Average performance (%)". Scale runs from 0 to 100 in increments of 20.
* **X-Axis (Bottom):** Labeled "Model scale (parameters)". Four categorical points are marked: `a-1`, `b-1`, `c-1`, `d-3` (presumably representing increasing model sizes).
* **Legend (Top-Left of each chart):**
* **Direct:** Gray line with circle markers.
* **CoT:** Blue line with circle markers.
* **CoC (ours):** Purple line with circle markers.
* **CoC (Python):** Red line with circle markers.
* **Horizontal Reference Lines (Dashed):**
* **Human Best:** Green dashed line, positioned near the top of the y-axis (~95%).
* **Human Average:** Yellow-green dashed line, positioned around 70%.
* **Random:** Orange dashed line, positioned around 25%.
### Detailed Analysis
#### Chart 1: All Tasks
* **Trend Verification:** All four methods show an upward trend as model scale increases. The slope is gentle from `a-1` to `c-1` and becomes significantly steeper from `c-1` to `d-3`.
* **Data Points (Approximate %):**
* **Direct (Gray):** `a-1`: ~30, `b-1`: ~30, `c-1`: ~30, `d-3`: ~55.
* **CoT (Blue):** `a-1`: ~28, `b-1`: ~30, `c-1`: ~31, `d-3`: ~72.
* **CoC (ours) (Purple):** `a-1`: ~33, `b-1`: ~36, `c-1`: ~41, `d-3`: ~84.
* **CoC (Python) (Red):** `a-1`: ~18, `b-1`: ~17, `c-1`: ~22, `d-3`: ~48.
* **Reference Lines:** Human Best ~95%, Human Average ~70%, Random ~25%.
#### Chart 2: NLP Tasks
* **Trend Verification:** Direct, CoT, and CoC (ours) show a moderate upward trend from `a-1` to `c-1`, followed by a very sharp increase to `d-3`. CoC (Python) shows a slight downward trend initially, then a modest increase.
* **Data Points (Approximate %):**
* **Direct (Gray):** `a-1`: ~32, `b-1`: ~35, `c-1`: ~38, `d-3`: ~68.
* **CoT (Blue):** `a-1`: ~32, `b-1`: ~35, `c-1`: ~35, `d-3`: ~74.
* **CoC (ours) (Purple):** `a-1`: ~32, `b-1`: ~36, `c-1`: ~38, `d-3`: ~74.
* **CoC (Python) (Red):** `a-1`: ~11, `b-1`: ~9, `c-1`: ~7, `d-3`: ~18.
* **Reference Lines:** Human Best ~97%, Human Average ~72%, Random ~30%.
#### Chart 3: Alg Tasks
* **Trend Verification:** All methods show an upward trend. CoC (ours) and CoC (Python) have the steepest slopes, especially from `c-1` to `d-3`. Direct has the shallowest slope.
* **Data Points (Approximate %):**
* **Direct (Gray):** `a-1`: ~21, `b-1`: ~23, `c-1`: ~26, `d-3`: ~41.
* **CoT (Blue):** `a-1`: ~21, `b-1`: ~23, `c-1`: ~26, `d-3`: ~71.
* **CoC (ours) (Purple):** `a-1`: ~34, `b-1`: ~36, `c-1`: ~46, `d-3`: ~95.
* **CoC (Python) (Red):** `a-1`: ~26, `b-1`: ~26, `c-1`: ~39, `d-3`: ~81.
* **Reference Lines:** Human Best ~92%, Human Average ~63%, Random ~21%.
#### Chart 4: Cross-task Prompted
* **Trend Verification:** Direct, CoT, and CoC (ours) show a relatively flat or slightly increasing trend from `a-1` to `c-1`, followed by a sharp increase to `d-3`. CoC (Python) shows a slight dip at `b-1` and `c-1` before rising.
* **Data Points (Approximate %):**
* **Direct (Gray):** `a-1`: ~24, `b-1`: ~28, `c-1`: ~25, `d-3`: ~50.
* **CoT (Blue):** `a-1`: ~24, `b-1`: ~20, `c-1`: ~23, `d-3`: ~55.
* **CoC (ours) (Purple):** `a-1`: ~25, `b-1`: ~27, `c-1`: ~30, `d-3`: ~61.
* **CoC (Python) (Red):** `a-1`: ~9, `b-1`: ~14, `c-1`: ~13, `d-3`: ~35.
* **Reference Lines:** Human Best ~95%, Human Average ~68%, Random ~25%.
### Key Observations
1. **Scale is Critical:** Performance for most methods, especially CoC (ours) and CoT, improves dramatically at the largest model scale (`d-3`), often surpassing Human Average.
2. **Method Hierarchy:** CoC (ours) consistently outperforms or matches CoT and Direct across all task categories and scales. CoC (Python) generally underperforms the other methods, except in "Alg Tasks" at the largest scale.
3. **Task-Specific Performance:** The "Alg Tasks" chart shows the highest peak performance, with CoC (ours) nearly reaching Human Best at `d-3`. "NLP Tasks" shows the closest clustering of Direct, CoT, and CoC (ours) at the largest scale.
4. **Human Benchmarks:** The "Human Best" line is a high bar (~92-97%) that is only approached by one method (CoC (ours)) in one category (Alg Tasks). "Human Average" (~63-72%) is a more commonly exceeded benchmark at the largest scale.
5. **Random Baseline:** The "Random" line (~21-30%) serves as a low-performance floor. All methods at scale `a-1` perform near or slightly above this baseline, with CoC (Python) often at or below it in smaller scales for NLP and Cross-task.
### Interpretation
The data demonstrates a clear scaling law for the evaluated prompting methods: larger models yield significantly better performance. The proposed method, "CoC (ours)", shows a superior scaling trajectory compared to standard Chain-of-Thought (CoT) and Direct prompting, suggesting it is more effective at leveraging increased model capacity.
The stark difference between "CoC (ours)" and "CoC (Python)" indicates that the specific implementation or formulation of the Chain-of-Code method is crucial; the "ours" variant is far more effective. The exceptional performance in "Alg Tasks" suggests the CoC approach is particularly well-suited for algorithmic or logical reasoning problems, where it nearly matches human expert performance at the largest scale.
The charts collectively argue that to achieve human-competitive performance on these diverse tasks, both a large-scale model and an advanced prompting strategy like CoC (ours) are necessary. The "Cross-task Prompted" results, which are generally lower, may indicate that generalizing across different task types with a single prompt is more challenging than performing well within a specific domain like NLP or Algorithms.
DECODING INTELLIGENCE...