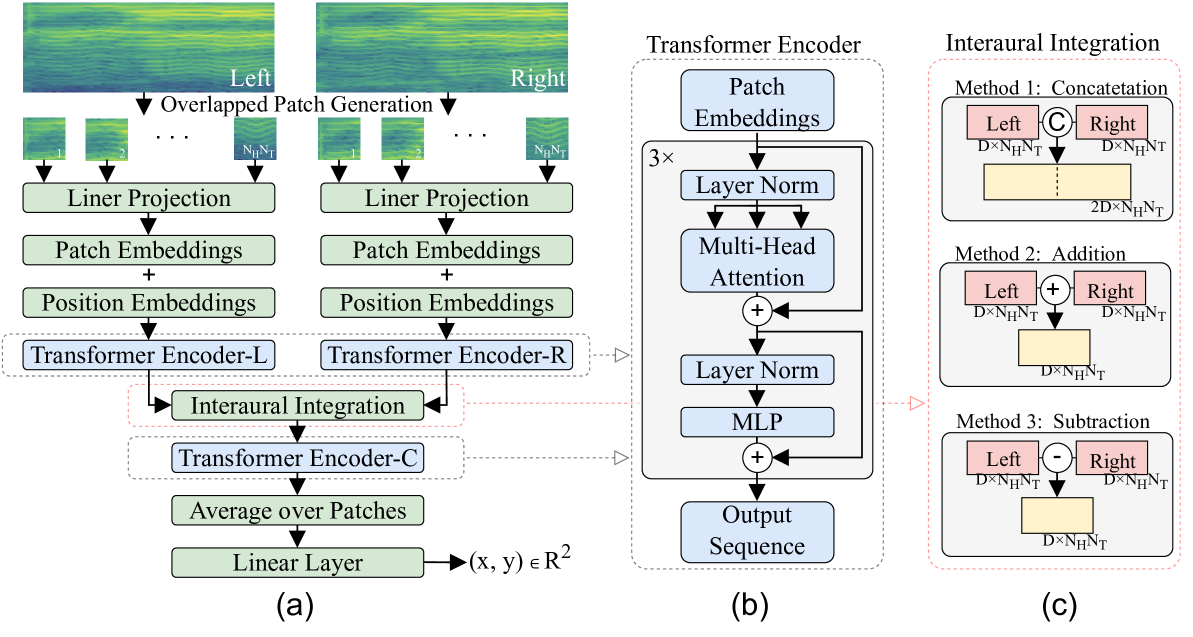
## Diagram: Transformer-Based Stereo Vision Architecture for Depth Estimation
### Overview
The diagram illustrates a transformer-based architecture for stereo vision depth estimation, divided into three components: (a) the overall system workflow, (b) detailed transformer encoder structure, and (c) interaural integration methods. The system processes stereo image pairs to estimate depth maps through patch embeddings, transformer encoding, and fusion of left/right view information.
### Components/Axes
#### Part (a): System Workflow
1. **Input**: Stereo image pair (Left/Right views) with overlapping patches.
2. **Preprocessing**:
- Linear Projection → Patch Embeddings
- Position Embeddings added to patch embeddings
3. **Encoding**:
- Separate Transformer Encoders (L for Left, R for Right)
- Interaural Integration combines L and R outputs
4. **Postprocessing**:
- Transformer Encoder-C (combined encoder)
- Average over patches → Linear Layer (outputs (x, y) ∈ ℝ²)
#### Part (b): Transformer Encoder Details
1. **Core Components**:
- Patch Embeddings (3×3 grid)
- Layer Normalization
- Multi-Head Attention
- MLP (Multi-Layer Perceptron)
2. **Flow**:
- Input → Patch Embeddings → Layer Norm → Multi-Head Attention → Layer Norm → MLP → Output Sequence
#### Part (c): Interaural Integration Methods
1. **Method 1: Concatenation**
- Input: Left (D×N_H×N_T) and Right (D×N_H×N_T)
- Output: 2D×N_H×N_T
2. **Method 2: Addition**
- Input: Left (D×N_H×N_T) + Right (D×N_H×N_T)
- Output: D×N_H×N_T
3. **Method 3: Subtraction**
- Input: Left (D×N_H×N_T) - Right (D×N_H×N_T)
- Output: D×N_H×N_T
### Detailed Analysis
- **Patch Generation**: Overlapping patches (N_P×N_P) extracted from both views.
- **Embeddings**: Patch and position embeddings encode spatial information.
- **Transformer Encoders**:
- Encoder-L/R process left/right views independently.
- Encoder-C integrates features from both views.
- **Integration Methods**:
- Concatenation preserves full spatial-temporal information.
- Addition/Subtraction create difference maps for disparity estimation.
### Key Observations
1. **Stereo Fusion**: The architecture explicitly models left/right view relationships through dedicated integration methods.
2. **Transformer Depth**: Uses standard transformer components (attention, MLP) adapted for vision tasks.
3. **Output Structure**: Final linear layer maps to 2D coordinates (x, y), likely representing depth estimation.
### Interpretation
This architecture demonstrates a vision transformer (ViT) approach to stereo depth estimation, leveraging:
1. **Multi-View Processing**: Separate encoders for left/right views maintain view-specific features.
2. **Feature Fusion**: Three integration methods (concat/add/subtract) enable flexible combination of view information.
3. **Depth Representation**: The 2D output suggests a coordinate-based depth map rather than per-pixel disparity.
The use of transformer encoders allows the model to capture long-range spatial dependencies crucial for accurate depth estimation, while the interaural integration methods provide multiple pathways to combine stereo information. The architecture's design suggests a focus on both feature-level fusion (addition/subtraction) and holistic view combination (concatenation).