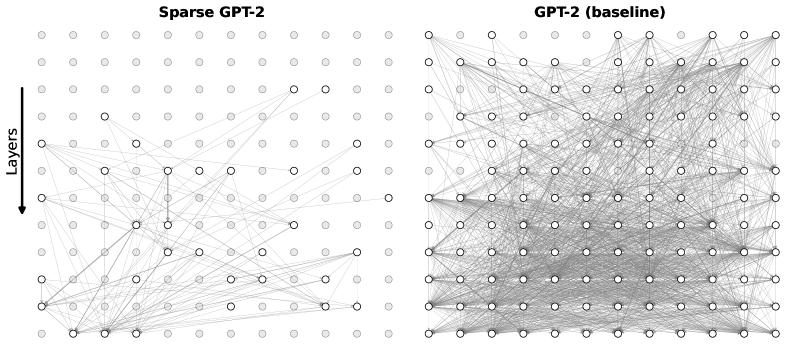
\n
## Diagram: Network Architecture Comparison - Sparse GPT-2 vs. GPT-2 (Baseline)
### Overview
The image presents a visual comparison of the network architectures of two GPT-2 models: a "Sparse GPT-2" and a standard "GPT-2 (baseline)". The diagrams depict the connections between nodes representing neurons across different layers of the networks. The primary difference highlighted is the density of connections – the Sparse GPT-2 has significantly fewer connections than the baseline GPT-2.
### Components/Axes
The diagrams do not have traditional axes. However, the vertical dimension represents "Layers", indicated by a label and arrow on the left diagram. Each diagram consists of nodes (circles) and connections (lines) between them. The diagrams are positioned side-by-side for direct comparison.
### Detailed Analysis or Content Details
**Sparse GPT-2 (Left Diagram):**
* The diagram shows approximately 10 layers, with roughly 10-12 nodes per layer.
* The connections are sparse, meaning each node is connected to only a few other nodes in adjacent layers.
* The connections appear to be somewhat random, but there's a clear pattern of connections between layers.
* The label "Sparse GPT-2" is positioned at the top-center of the diagram.
* The "Layers" label and arrow are positioned on the left side, indicating the vertical direction represents layers.
**GPT-2 (Baseline) (Right Diagram):**
* The diagram also shows approximately 10 layers, with roughly 10-12 nodes per layer.
* The connections are dense, meaning each node is connected to many other nodes in adjacent layers. Almost every node is connected to every other node in the adjacent layers.
* The connections form a nearly complete graph between adjacent layers.
* The label "GPT-2 (baseline)" is positioned at the top-center of the diagram.
**Quantitative Estimation (Approximate):**
* Sparse GPT-2: Approximately 100 nodes total. Estimated 100-150 connections.
* GPT-2 (Baseline): Approximately 100 nodes total. Estimated 800-1000 connections.
### Key Observations
The most striking observation is the difference in connection density. The Sparse GPT-2 has a dramatically reduced number of connections compared to the baseline GPT-2. This suggests that the Sparse GPT-2 model employs techniques like pruning or sparse attention to reduce the computational cost and potentially the model size. The baseline GPT-2 appears to be a fully connected or densely connected network.
### Interpretation
The diagrams illustrate a key difference in architectural design between the two GPT-2 models. The Sparse GPT-2 likely aims to achieve comparable performance to the baseline GPT-2 with a significantly reduced number of parameters and computational requirements. This is achieved by selectively removing connections, effectively creating a sparse network. The baseline GPT-2 represents a more traditional, densely connected neural network architecture. The comparison highlights the trade-off between model complexity (number of parameters) and performance. Sparse models are often more efficient and easier to deploy, while dense models may achieve higher accuracy given sufficient resources. The diagrams suggest that the sparse model is an attempt to improve efficiency without sacrificing too much performance. The diagrams do not provide any information about the performance of the models, only their structure.