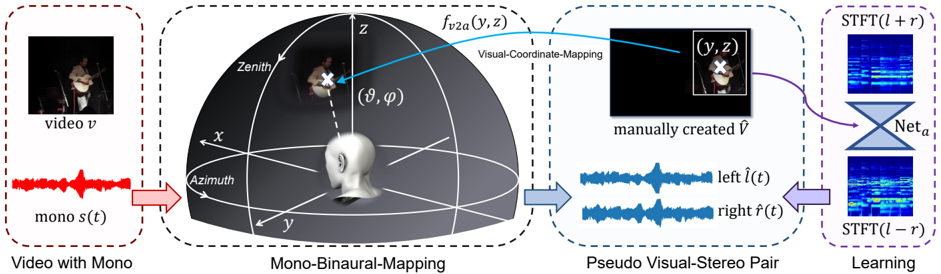
\n
## Diagram: Spatial Audio Processing Pipeline
### Overview
This diagram illustrates a pipeline for converting monaural audio from a video source into a pseudo-stereo pair, and then using this to train a neural network for spatial audio processing. The pipeline consists of four main stages: Video with Mono, Mono-Binaural-Mapping, Pseudo Visual-Stereo Pair, and Learning. The diagram uses a spherical coordinate system to map visual information to spatial audio cues.
### Components/Axes
The diagram is divided into four sections, each enclosed by a dashed-line rectangle and labeled:
1. **Video with Mono:** Contains a video frame and a monaural audio waveform.
2. **Mono-Binaural-Mapping:** Depicts a 3D spherical coordinate system with labels for Azimuth, Zenith, and the coordinates (θ, φ).
3. **Pseudo Visual-Stereo Pair:** Shows two video frames with corresponding left and right audio waveforms.
4. **Learning:** Illustrates a neural network (Net<sub>a</sub>) processing Short-Time Fourier Transform (STFT) representations of the audio.
Key labels include:
* **video v:** Represents the input video.
* **mono ˆf(t):** Represents the monaural audio waveform.
* **f<sub>v2a</sub>(y, z):** Represents the visual-coordinate mapping function.
* **manually created ˆf:** Represents the manually created audio.
* **left ˆf(t):** Represents the left audio channel waveform.
* **right ˆf(t):** Represents the right audio channel waveform.
* **Net<sub>a</sub>:** Represents the neural network.
* **STFT(t + r):** Represents the Short-Time Fourier Transform of the left channel.
* **STFT(t - r):** Represents the Short-Time Fourier Transform of the right channel.
* **Azimuth:** Angle in the x-y plane.
* **Zenith:** Angle from the z-axis.
* **(θ, φ):** Spherical coordinates.
* **(y, z):** Visual coordinates.
### Detailed Analysis or Content Details
1. **Video with Mono:** A video frame showing a person playing a violin is present. Below it is a red waveform labeled "mono ˆf(t)". The waveform appears to be a typical audio signal with varying amplitude over time.
2. **Mono-Binaural-Mapping:** A 3D sphere is shown with a coordinate system (x, y, z). A person is positioned within the sphere, and an arrow points from the person to the coordinates (θ, φ). Another arrow points from the coordinates (y, z) to the next stage. The sphere is bisected by the x-y plane, labeled "Azimuth", and the z-axis is labeled "Zenith".
3. **Pseudo Visual-Stereo Pair:** Two video frames are shown, both displaying the same person playing the violin. Above the left frame is a blue waveform labeled "left ˆf(t)", and above the right frame is a blue waveform labeled "right ˆf(t)".
4. **Learning:** Two spectrograms are shown, one labeled "STFT(t + r)" and the other labeled "STFT(t - r)". These represent the Short-Time Fourier Transform of the left and right audio channels, respectively. Both spectrograms are fed into a neural network labeled "Net<sub>a</sub>". The network has a triangular shape, suggesting a processing or transformation stage.
### Key Observations
The diagram demonstrates a process of mapping visual information from a video to spatial audio cues. The use of spherical coordinates suggests an attempt to represent sound source location in 3D space. The creation of a pseudo-stereo pair from monaural audio indicates a method for generating spatial audio effects. The neural network is likely trained to learn the relationship between visual cues and spatial audio characteristics.
### Interpretation
This diagram outlines a system for generating spatial audio from video content. The core idea is to use visual information (the position of sound sources in the video frame) to create a binaural audio experience. The "Mono-Binaural-Mapping" stage is crucial, as it defines how visual coordinates are translated into spatial audio cues (left/right channel differences). The neural network is then trained to refine this mapping, potentially learning to create more realistic and immersive spatial audio. The use of STFTs suggests that the network operates in the frequency domain, allowing it to manipulate the spectral characteristics of the audio to create spatial effects. The manually created audio suggests a ground truth or target for the mapping process. The diagram suggests a data-driven approach to spatial audio rendering, where the neural network learns to associate visual cues with appropriate audio spatialization. The system could be used for applications such as virtual reality, augmented reality, or immersive video playback.