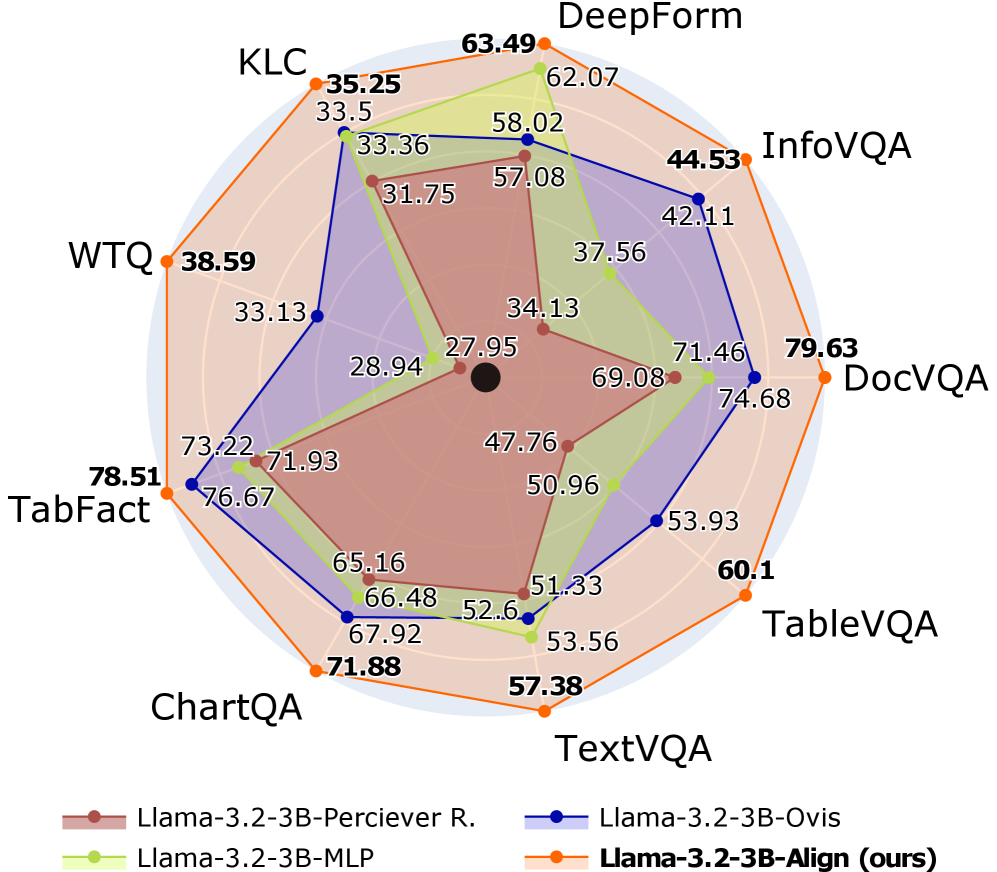
## Radar Chart: Model Performance Comparison
### Overview
The image is a radar chart comparing the performance of four different language models (Llama-3.2-3B-Perciever R., Llama-3.2-3B-MLP, Llama-3.2-3B-Ovis, and Llama-3.2-3B-Align (ours)) across seven different tasks: KLC, DeepForm, InfoVQA, DocVQA, TableVQA, TextVQA, ChartQA, WTQ, and TabFact. The chart visualizes the performance of each model on each task, with higher values indicating better performance.
### Components/Axes
* **Chart Type**: Radar Chart (also known as a spider chart or star chart)
* **Axes**: The chart has seven axes, each representing a different task. The axes radiate outwards from a central point.
* **Tasks (Categories)**:
* KLC (top-left)
* DeepForm (top)
* InfoVQA (top-right)
* DocVQA (right)
* TableVQA (bottom-right)
* TextVQA (bottom)
* ChartQA (bottom-left)
* TabFact (left)
* WTQ (left)
* **Data Series (Models)**:
* Llama-3.2-3B-Perciever R. (brown)
* Llama-3.2-3B-MLP (light green)
* Llama-3.2-3B-Ovis (dark blue)
* Llama-3.2-3B-Align (ours) (orange)
* **Scale**: The chart has a radial scale, with values increasing from the center outwards. There are concentric circles indicating increasing values, but no explicit numerical labels on these circles. The values for each model on each task are displayed numerically next to the corresponding data point.
* **Legend**: Located at the bottom of the chart, the legend identifies each model by color and name.
### Detailed Analysis
**Llama-3.2-3B-Perciever R. (brown)**:
* KLC: 31.75
* DeepForm: 58.02
* InfoVQA: 57.08
* DocVQA: 71.46
* TableVQA: 51.33
* TextVQA: 52.6
* ChartQA: 65.16
* TabFact: 71.93
* WTQ: 28.94
**Llama-3.2-3B-MLP (light green)**:
* KLC: 33.5
* DeepForm: 62.07
* InfoVQA: 37.56
* DocVQA: 69.08
* TableVQA: 50.96
* TextVQA: 53.56
* ChartQA: 67.92
* TabFact: 73.22
* WTQ: 33.13
**Llama-3.2-3B-Ovis (dark blue)**:
* KLC: 33.36
* DeepForm: 44.53
* InfoVQA: 42.11
* DocVQA: 74.68
* TableVQA: 53.93
* TextVQA: 66.48
* ChartQA: 76.67
* TabFact: 76.67
* WTQ: 33.13
**Llama-3.2-3B-Align (ours) (orange)**:
* KLC: 35.25
* DeepForm: 63.49
* InfoVQA: 44.53
* DocVQA: 79.63
* TableVQA: 60.1
* TextVQA: 57.38
* ChartQA: 71.88
* TabFact: 78.51
* WTQ: 38.59
### Key Observations
* **Overall Performance**: Llama-3.2-3B-Align (ours) generally outperforms the other models across most tasks, as indicated by the larger area enclosed by the orange line.
* **Task-Specific Performance**:
* DocVQA: All models perform relatively well on DocVQA, with Llama-3.2-3B-Align (ours) achieving the highest score (79.63).
* KLC: All models perform relatively poorly on KLC, with Llama-3.2-3B-Align (ours) achieving the highest score (35.25).
* DeepForm: All models perform relatively well on DeepForm, with Llama-3.2-3B-Align (ours) achieving the highest score (63.49).
* TabFact: All models perform relatively well on TabFact, with Llama-3.2-3B-Align (ours) achieving the highest score (78.51).
* **Model Consistency**: Llama-3.2-3B-Ovis (dark blue) shows relatively consistent performance across tasks, while Llama-3.2-3B-Perciever R. (brown) has more variability.
### Interpretation
The radar chart provides a clear visual comparison of the performance of the four language models across the seven tasks. The Llama-3.2-3B-Align (ours) model appears to be the most effective overall, achieving the highest scores on several tasks. The chart highlights the strengths and weaknesses of each model on specific tasks, which could inform future model development and task selection. The relatively low scores on KLC for all models suggest that this task may be particularly challenging. The high scores on DocVQA and TabFact suggest that these tasks are relatively easier for the models.