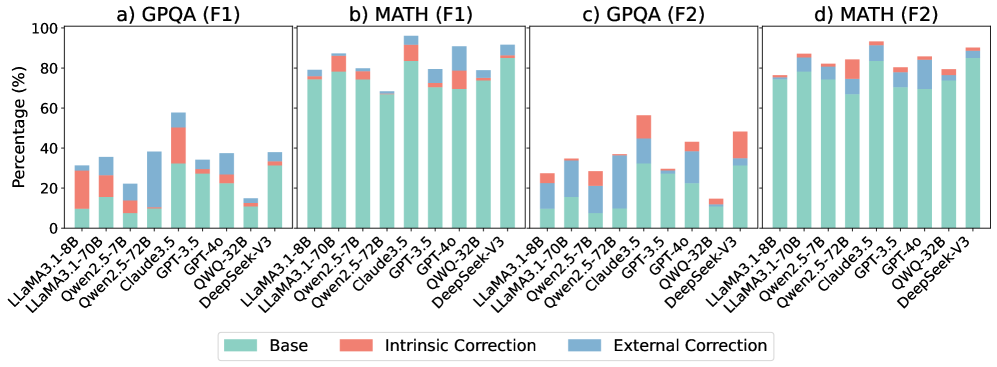
## Stacked Bar Chart: Model Performance on GPQA and MATH Datasets
### Overview
The image presents four stacked bar charts comparing the performance of various language models on the GPQA and MATH datasets, evaluated using F1 scores. The charts are arranged in a 2x2 grid, with GPQA and MATH results shown for two different evaluation settings (F1). Each bar represents a model, and the bar is segmented into three components: "Base" performance, "Intrinsic Correction," and "External Correction."
### Components/Axes
* **Titles:**
* a) GPQA (F1)
* b) MATH (F1)
* c) GPQA (F2)
* d) MATH (F2)
* **Y-axis:**
* Label: "Percentage (%)"
* Scale: 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-axis:**
* Labels: Model names (see below).
* **Legend:** Located at the bottom of the image.
* Base (light teal)
* Intrinsic Correction (light coral)
* External Correction (light blue)
* **Models (X-axis labels, same for all charts):**
* LLaMA3.1-8B
* LLaMA3.1-70B
* Qwen2.5-7B
* Qwen2.5-72B
* Claude3.5
* GPT-3.5
* GPT-4o
* QWQ-32B
* DeepSeek-V3
### Detailed Analysis
**a) GPQA (F1)**
* **LLaMA3.1-8B:** Base ~10%, Intrinsic ~15%, External ~5%, Total ~30%
* **LLaMA3.1-70B:** Base ~15%, Intrinsic ~10%, External ~10%, Total ~35%
* **Qwen2.5-7B:** Base ~5%, Intrinsic ~5%, External ~10%, Total ~20%
* **Qwen2.5-72B:** Base ~10%, Intrinsic ~5%, External ~5%, Total ~20%
* **Claude3.5:** Base ~10%, Intrinsic ~25%, External ~25%, Total ~60%
* **GPT-3.5:** Base ~30%, Intrinsic ~10%, External ~5%, Total ~45%
* **GPT-4o:** Base ~20%, Intrinsic ~5%, External ~10%, Total ~35%
* **QWQ-32B:** Base ~20%, Intrinsic ~5%, External ~5%, Total ~30%
* **DeepSeek-V3:** Base ~10%, Intrinsic ~0%, External ~0%, Total ~10%
**b) MATH (F1)**
* **LLaMA3.1-8B:** Base ~10%, Intrinsic ~0%, External ~0%, Total ~10%
* **LLaMA3.1-70B:** Base ~75%, Intrinsic ~5%, External ~5%, Total ~85%
* **Qwen2.5-7B:** Base ~70%, Intrinsic ~5%, External ~5%, Total ~80%
* **Qwen2.5-72B:** Base ~70%, Intrinsic ~5%, External ~5%, Total ~80%
* **Claude3.5:** Base ~70%, Intrinsic ~5%, External ~5%, Total ~80%
* **GPT-3.5:** Base ~80%, Intrinsic ~5%, External ~5%, Total ~90%
* **GPT-4o:** Base ~70%, Intrinsic ~5%, External ~5%, Total ~80%
* **QWQ-32B:** Base ~85%, Intrinsic ~5%, External ~5%, Total ~95%
* **DeepSeek-V3:** Base ~75%, Intrinsic ~0%, External ~0%, Total ~75%
**c) GPQA (F2)**
* **LLaMA3.1-8B:** Base ~10%, Intrinsic ~5%, External ~10%, Total ~25%
* **LLaMA3.1-70B:** Base ~25%, Intrinsic ~5%, External ~5%, Total ~35%
* **Qwen2.5-7B:** Base ~15%, Intrinsic ~5%, External ~5%, Total ~25%
* **Qwen2.5-72B:** Base ~25%, Intrinsic ~0%, External ~5%, Total ~30%
* **Claude3.5:** Base ~30%, Intrinsic ~15%, External ~10%, Total ~55%
* **GPT-3.5:** Base ~10%, Intrinsic ~5%, External ~5%, Total ~20%
* **GPT-4o:** Base ~25%, Intrinsic ~10%, External ~10%, Total ~45%
* **QWQ-32B:** Base ~5%, Intrinsic ~0%, External ~0%, Total ~5%
* **DeepSeek-V3:** Base ~20%, Intrinsic ~10%, External ~10%, Total ~40%
**d) MATH (F2)**
* **LLaMA3.1-8B:** Base ~75%, Intrinsic ~5%, External ~5%, Total ~85%
* **LLaMA3.1-70B:** Base ~75%, Intrinsic ~5%, External ~5%, Total ~85%
* **Qwen2.5-7B:** Base ~70%, Intrinsic ~5%, External ~5%, Total ~80%
* **Qwen2.5-72B:** Base ~75%, Intrinsic ~5%, External ~5%, Total ~85%
* **Claude3.5:** Base ~75%, Intrinsic ~5%, External ~5%, Total ~85%
* **GPT-3.5:** Base ~80%, Intrinsic ~5%, External ~5%, Total ~90%
* **GPT-4o:** Base ~75%, Intrinsic ~5%, External ~5%, Total ~85%
* **QWQ-32B:** Base ~85%, Intrinsic ~5%, External ~5%, Total ~95%
* **DeepSeek-V3:** Base ~70%, Intrinsic ~5%, External ~5%, Total ~80%
### Key Observations
* The MATH dataset generally yields higher F1 scores than the GPQA dataset across all models.
* The "Base" performance component dominates the MATH results, while "Intrinsic Correction" and "External Correction" contribute relatively little.
* On GPQA, the "Intrinsic Correction" and "External Correction" components play a more significant role, especially for models like Claude3.5.
* The performance of different models varies significantly on GPQA, with Claude3.5 and GPT-4o showing relatively higher scores.
* DeepSeek-V3 shows relatively low performance on GPQA compared to MATH.
* QWQ-32B consistently achieves high scores on the MATH dataset.
### Interpretation
The charts illustrate the performance of various language models on two different tasks: GPQA (likely a general-purpose question answering task) and MATH (mathematical problem-solving). The stacked bars break down the performance into "Base" (initial performance), "Intrinsic Correction" (improvements from internal mechanisms), and "External Correction" (improvements from external tools or data).
The high "Base" performance on MATH suggests that many models are already proficient in mathematical reasoning. The relatively small contributions from "Intrinsic Correction" and "External Correction" indicate that these models may not benefit significantly from additional correction mechanisms for this task.
In contrast, the GPQA results show a greater reliance on "Intrinsic Correction" and "External Correction," suggesting that the models require more assistance to perform well on this task. The varying performance across models on GPQA highlights the differences in their ability to handle general question answering.
The difference in performance between the two datasets suggests that mathematical reasoning is a relatively easier task for these models compared to general question answering. The data also indicates that certain models, like Claude3.5, are better equipped to leverage correction mechanisms for improved performance on complex tasks like GPQA.