## Bar Chart: Model Performance by Medical Specialty
### Overview
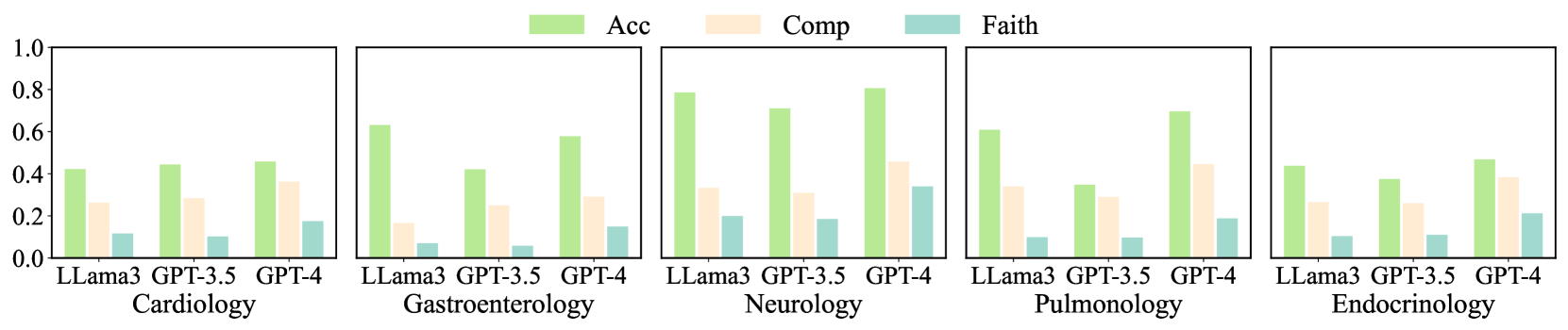
The image presents a series of bar charts comparing the performance of three language models (LLama3, GPT-3.5, and GPT-4) across five medical specialties: Cardiology, Gastroenterology, Neurology, Pulmonology, and Endocrinology. The performance is measured by three metrics: Accuracy (Acc), Completeness (Comp), and Faithfulness (Faith). Each specialty has its own subplot, showing the performance of each model on the three metrics.
### Components/Axes
* **X-axis:** Categorical, representing the language models: LLama3, GPT-3.5, and GPT-4. Each model is evaluated within each medical specialty.
* **Y-axis:** Numerical, ranging from 0.0 to 1.0, representing the performance score.
* **Subplots:** Five subplots, each representing a different medical specialty: Cardiology, Gastroenterology, Neurology, Pulmonology, and Endocrinology.
* **Legend:** Located at the top of the image.
* Acc: Accuracy (light green)
* Comp: Completeness (light orange)
* Faith: Faithfulness (light blue)
### Detailed Analysis
**Cardiology:**
* **Acc (light green):** LLama3 ~0.45, GPT-3.5 ~0.45, GPT-4 ~0.47
* **Comp (light orange):** LLama3 ~0.27, GPT-3.5 ~0.30, GPT-4 ~0.37
* **Faith (light blue):** LLama3 ~0.12, GPT-3.5 ~0.10, GPT-4 ~0.12
**Gastroenterology:**
* **Acc (light green):** LLama3 ~0.65, GPT-3.5 ~0.43, GPT-4 ~0.78
* **Comp (light orange):** LLama3 ~0.15, GPT-3.5 ~0.25, GPT-4 ~0.30
* **Faith (light blue):** LLama3 ~0.08, GPT-3.5 ~0.08, GPT-4 ~0.15
**Neurology:**
* **Acc (light green):** LLama3 ~0.80, GPT-3.5 ~0.73, GPT-4 ~0.85
* **Comp (light orange):** LLama3 ~0.30, GPT-3.5 ~0.35, GPT-4 ~0.45
* **Faith (light blue):** LLama3 ~0.20, GPT-3.5 ~0.10, GPT-4 ~0.15
**Pulmonology:**
* **Acc (light green):** LLama3 ~0.45, GPT-3.5 ~0.35, GPT-4 ~0.70
* **Comp (light orange):** LLama3 ~0.25, GPT-3.5 ~0.35, GPT-4 ~0.30
* **Faith (light blue):** LLama3 ~0.10, GPT-3.5 ~0.10, GPT-4 ~0.20
**Endocrinology:**
* **Acc (light green):** LLama3 ~0.40, GPT-3.5 ~0.40, GPT-4 ~0.50
* **Comp (light orange):** LLama3 ~0.28, GPT-3.5 ~0.28, GPT-4 ~0.30
* **Faith (light blue):** LLama3 ~0.10, GPT-3.5 ~0.12, GPT-4 ~0.22
### Key Observations
* **Accuracy:** GPT-4 generally has the highest accuracy across all specialties, with Neurology showing the highest accuracy scores overall.
* **Completeness:** Completeness scores are generally lower than accuracy scores across all models and specialties. GPT-4 tends to have slightly higher completeness scores.
* **Faithfulness:** Faithfulness scores are the lowest among the three metrics, indicating a potential area for improvement for all models.
* **Specialty Variation:** The performance of the models varies significantly across different medical specialties, suggesting that some specialties are more challenging than others.
### Interpretation
The bar charts provide a comparative analysis of the performance of LLama3, GPT-3.5, and GPT-4 in different medical domains. GPT-4 generally outperforms the other models in terms of accuracy, completeness, and faithfulness. However, the low faithfulness scores across all models suggest that there is room for improvement in generating reliable and trustworthy information. The variation in performance across specialties highlights the importance of tailoring language models to specific domains to optimize their effectiveness. The data suggests that while GPT-4 is a strong performer, further research and development are needed to improve the faithfulness of language models in medical applications.