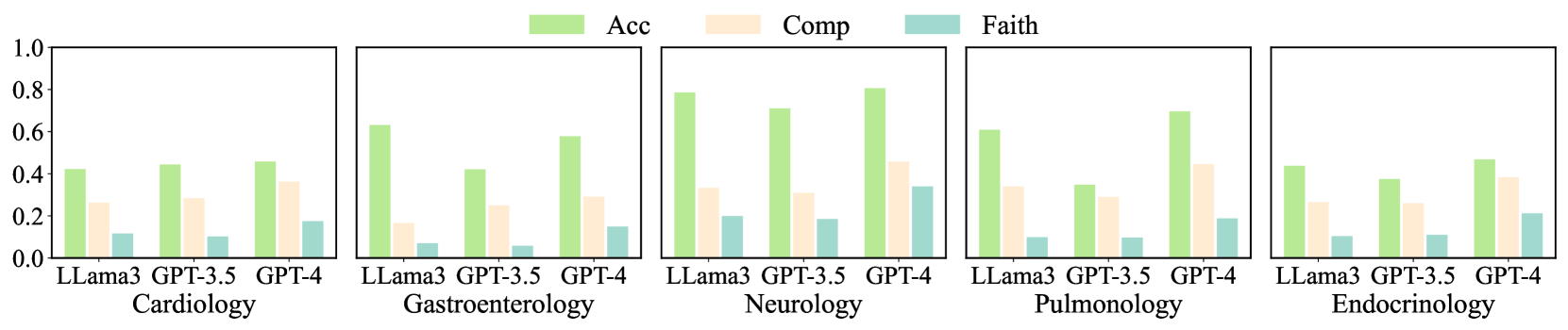
## Bar Chart: Performance Comparison of LLMs Across Medical Specialties
### Overview
The image presents a series of five bar charts, each representing the performance of three Large Language Models (LLMs) – LLama3, GPT-3.5, and GPT-4 – across five different medical specialties: Cardiology, Gastroenterology, Neurology, Pulmonology, and Endocrinology. The performance is measured by three metrics: Accuracy (Acc), Completeness (Comp), and Faithfulness (Faith). Each bar chart displays the values of these metrics for each LLM within a specific specialty.
### Components/Axes
* **X-axis:** Represents the LLM models: LLama3, GPT-3.5, and GPT-4.
* **Y-axis:** Represents the performance scores, ranging from 0.0 to 1.0.
* **Legend (Top-Center):**
* Green: Acc (Accuracy)
* Yellow: Comp (Completeness)
* Light Blue: Faith (Faithfulness)
* **Chart Titles (Bottom):** Each chart is labeled with the corresponding medical specialty.
### Detailed Analysis
**1. Cardiology**
* LLama3: Acc ≈ 0.32, Comp ≈ 0.16, Faith ≈ 0.08
* GPT-3.5: Acc ≈ 0.44, Comp ≈ 0.24, Faith ≈ 0.16
* GPT-4: Acc ≈ 0.48, Comp ≈ 0.32, Faith ≈ 0.24
**2. Gastroenterology**
* LLama3: Acc ≈ 0.28, Comp ≈ 0.12, Faith ≈ 0.04
* GPT-3.5: Acc ≈ 0.56, Comp ≈ 0.28, Faith ≈ 0.16
* GPT-4: Acc ≈ 0.72, Comp ≈ 0.44, Faith ≈ 0.28
**3. Neurology**
* LLama3: Acc ≈ 0.24, Comp ≈ 0.16, Faith ≈ 0.12
* GPT-3.5: Acc ≈ 0.76, Comp ≈ 0.52, Faith ≈ 0.32
* GPT-4: Acc ≈ 0.84, Comp ≈ 0.60, Faith ≈ 0.40
**4. Pulmonology**
* LLama3: Acc ≈ 0.28, Comp ≈ 0.16, Faith ≈ 0.08
* GPT-3.5: Acc ≈ 0.48, Comp ≈ 0.28, Faith ≈ 0.16
* GPT-4: Acc ≈ 0.56, Comp ≈ 0.36, Faith ≈ 0.24
**5. Endocrinology**
* LLama3: Acc ≈ 0.20, Comp ≈ 0.12, Faith ≈ 0.04
* GPT-3.5: Acc ≈ 0.36, Comp ≈ 0.20, Faith ≈ 0.12
* GPT-4: Acc ≈ 0.44, Comp ≈ 0.28, Faith ≈ 0.16
### Key Observations
* GPT-4 consistently outperforms both LLama3 and GPT-3.5 across all medical specialties and all metrics.
* LLama3 generally exhibits the lowest performance across all categories.
* Accuracy (Acc) scores are generally higher than Completeness (Comp) and Faithfulness (Faith) scores for all models and specialties.
* The largest performance differences between models are observed in Neurology and Gastroenterology.
* Faithfulness scores are consistently the lowest across all specialties and models.
### Interpretation
The data suggests that GPT-4 is the most capable LLM for medical applications, demonstrating superior accuracy, completeness, and faithfulness compared to GPT-3.5 and LLama3. The consistent outperformance of GPT-4 highlights the importance of model size and training data quality in achieving reliable performance in specialized domains like medicine. The lower faithfulness scores across all models suggest a potential area for improvement, indicating that these models may sometimes generate responses that are not entirely grounded in factual information. The variability in performance across different medical specialties suggests that the complexity and available data within each specialty may influence the LLM's ability to perform effectively. The relatively low performance of LLama3 indicates that it may not be suitable for complex medical tasks without further refinement. The gap between accuracy and faithfulness suggests that while the models can often provide correct answers, they may not always be able to justify or support those answers with reliable evidence.