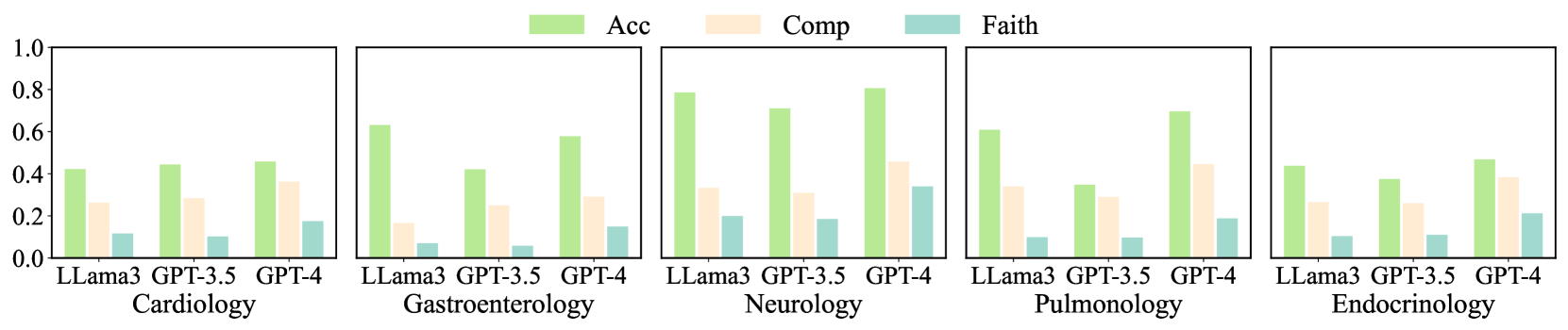
## Grouped Bar Chart: Model Performance Across Medical Specialties
### Overview
The image displays a series of five grouped bar charts arranged horizontally. Each chart compares the performance of three large language models (LLMs) across three evaluation metrics within a specific medical specialty. The overall purpose is to benchmark model capabilities in specialized medical domains.
### Components/Axes
* **Chart Type:** Grouped Bar Chart (5 panels).
* **Legend:** Located at the top center of the entire figure.
* **Green Bar:** "Acc" (Likely abbreviation for Accuracy).
* **Beige/Light Orange Bar:** "Comp" (Likely abbreviation for Comprehensiveness or Completeness).
* **Teal/Light Blue Bar:** "Faith" (Likely abbreviation for Faithfulness).
* **Y-Axis:** Common to all five panels. Labeled with numerical values from `0.0` to `1.0` in increments of `0.2`. This represents a normalized score or probability.
* **X-Axis (Per Panel):** Lists three models: `LLama3`, `GPT-3.5`, `GPT-4`.
* **Panel Titles (Bottom Labels):** Each panel is labeled with a medical specialty:
1. Cardiology
2. Gastroenterology
3. Neurology
4. Pulmonology
5. Endocrinology
### Detailed Analysis
**Panel 1: Cardiology**
* **LLama3:** Acc ≈ 0.42, Comp ≈ 0.26, Faith ≈ 0.12.
* **GPT-3.5:** Acc ≈ 0.44, Comp ≈ 0.28, Faith ≈ 0.11.
* **GPT-4:** Acc ≈ 0.45, Comp ≈ 0.36, Faith ≈ 0.18.
* **Trend:** Acc scores are similar and moderate. Comp and Faith scores are lower, with GPT-4 showing a notable increase in Comp.
**Panel 2: Gastroenterology**
* **LLama3:** Acc ≈ 0.63, Comp ≈ 0.17, Faith ≈ 0.07.
* **GPT-3.5:** Acc ≈ 0.42, Comp ≈ 0.25, Faith ≈ 0.06.
* **GPT-4:** Acc ≈ 0.58, Comp ≈ 0.29, Faith ≈ 0.15.
* **Trend:** LLama3 has the highest Acc but the lowest Comp and Faith. GPT-4 shows a balanced profile with the highest Faith in this panel.
**Panel 3: Neurology**
* **LLama3:** Acc ≈ 0.79, Comp ≈ 0.33, Faith ≈ 0.20.
* **GPT-3.5:** Acc ≈ 0.71, Comp ≈ 0.30, Faith ≈ 0.19.
* **GPT-4:** Acc ≈ 0.80, Comp ≈ 0.45, Faith ≈ 0.34.
* **Trend:** This specialty shows the highest overall Acc scores. GPT-4 leads in all three metrics, with a particularly strong Comp score.
**Panel 4: Pulmonology**
* **LLama3:** Acc ≈ 0.61, Comp ≈ 0.33, Faith ≈ 0.10.
* **GPT-3.5:** Acc ≈ 0.35, Comp ≈ 0.29, Faith ≈ 0.10.
* **GPT-4:** Acc ≈ 0.70, Comp ≈ 0.44, Faith ≈ 0.19.
* **Trend:** GPT-4 significantly outperforms the other models in Acc and Comp. GPT-3.5 shows a notable dip in Acc compared to other specialties.
**Panel 5: Endocrinology**
* **LLama3:** Acc ≈ 0.44, Comp ≈ 0.26, Faith ≈ 0.11.
* **GPT-3.5:** Acc ≈ 0.38, Comp ≈ 0.26, Faith ≈ 0.12.
* **GPT-4:** Acc ≈ 0.47, Comp ≈ 0.38, Faith ≈ 0.21.
* **Trend:** Performance is generally lower and more uniform across models compared to other specialties. GPT-4 maintains a slight lead.
### Key Observations
1. **Metric Hierarchy:** Across all models and specialties, the `Acc` (green) score is consistently the highest, followed by `Comp` (beige), with `Faith` (teal) being the lowest. This suggests a potential trade-off or difficulty in achieving high faithfulness.
2. **Model Performance:** `GPT-4` consistently achieves the highest or near-highest scores in all three metrics across every specialty. `LLama3` often shows strong `Acc` but weaker `Comp` and `Faith`. `GPT-3.5` performance is more variable.
3. **Specialty Variance:** `Neurology` appears to be the specialty where models achieve the highest overall scores, particularly in `Acc`. `Cardiology` and `Endocrinology` show lower, more clustered performance.
4. **Notable Outlier:** In `Pulmonology`, `GPT-3.5`'s `Acc` score (~0.35) is significantly lower than its performance in other specialties and lower than both `LLama3` and `GPT-4` in the same panel.
### Interpretation
The data suggests a clear performance gradient among the evaluated LLMs in specialized medical question-answering or reasoning tasks, with `GPT-4` demonstrating superior capability. The consistent pattern of `Acc > Comp > Faith` indicates that while models can often arrive at correct answers (`Acc`), providing comprehensive (`Comp`) and, especially, faithful (`Faith`) justifications or information is more challenging. This has significant implications for clinical applications where explainability and reliability of the reasoning process are critical.
The variation across specialties implies that model knowledge or reasoning ability is not uniform across medicine. The high scores in Neurology might reflect a larger or more structured training corpus for that domain, while lower scores in Endocrinology could indicate a more complex or less represented knowledge base. The dip for `GPT-3.5` in Pulmonology warrants further investigation into potential dataset biases or model limitations for that specific domain. Overall, the chart provides a multi-faceted benchmark showing that model selection for medical AI should consider both the target specialty and the required balance between accuracy, comprehensiveness, and faithfulness.