\n
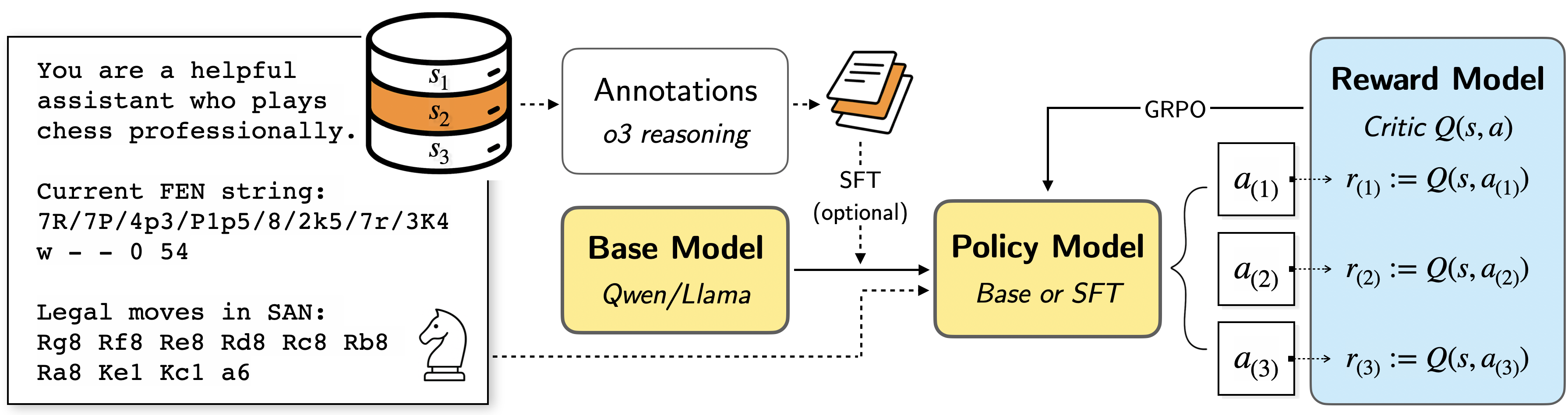
## Diagram: Chess Agent Training Pipeline
### Overview
This diagram illustrates the training pipeline for a chess-playing agent. It depicts the flow of data and models, starting from a base language model and culminating in a reward model used for reinforcement learning. The pipeline involves stages like annotation, supervised fine-tuning (SFT), policy model training, and reward model training using Generative Rollout Policy Optimization (GRPO).
### Components/Axes
The diagram consists of the following components:
* **Text Prompt:** "You are a helpful assistant who plays chess professionally."
* **Current FEN string:** "7R/7P/4p3/P1p5/8/2k5/7r/3K4 w - 0 54"
* **Legal moves in SAN:** "Rg8 Rxg8 Re8 Rd8 Rc8 Rb8 Ra8 Kel Kcl a6"
* **Base Model:** Labeled "Qwen/Llama"
* **Annotations:** Labeled "o3 reasoning"
* **SFT (optional):** Supervised Fine-Tuning
* **Policy Model:** Labeled "Base or SFT"
* **Reward Model:** Labeled "Critic Q(s, a)"
* **GRPO:** Generative Rollout Policy Optimization
* **States:** S1, S2, S3
* **Actions:** a(1), a(2), a(3)
* **Rewards:** r(1), r(2), r(3)
* **Chess Piece Icon:** A white chess knight.
### Detailed Analysis or Content Details
The diagram shows a data flow starting from a text prompt and a chess position (FEN string).
1. **Initial State:** The process begins with a text prompt defining the agent's role and a current chess position represented by the FEN string "7R/7P/4p3/P1p5/8/2k5/7r/3K4 w - 0 54". The side to move is white ("w"), there are no castling rights ("-"), and the halfmove clock is 0, with the fullmove number being 54.
2. **Legal Moves:** A list of legal moves in Standard Algebraic Notation (SAN) is provided: "Rg8 Rxg8 Re8 Rd8 Rc8 Rb8 Ra8 Kel Kcl a6".
3. **Base Model:** The initial model is a "Qwen/Llama" language model.
4. **Annotations:** The base model's output is annotated with "o3 reasoning". These annotations are used for supervised fine-tuning.
5. **SFT (Optional):** The base model can optionally be fine-tuned using the annotations via Supervised Fine-Tuning (SFT).
6. **Policy Model:** The output of either the base model or the SFT model becomes the "Policy Model".
7. **GRPO & Reward Model:** The policy model interacts with the environment (chess game) and generates actions. These actions are evaluated by a "Reward Model" (Critic Q(s, a)). The Reward Model provides a reward signal based on the state (s) and action (a).
8. **Reward Loop:** The diagram shows three iterations of this reward loop:
* Action a(1) results in reward r(1) = Q(s, a(1))
* Action a(2) results in reward r(2) = Q(s, a(2))
* Action a(3) results in reward r(3) = Q(s, a(3))
9. **GRPO Connection:** The Reward Model is connected to the Policy Model via "GRPO" (Generative Rollout Policy Optimization), indicating that the reward signal is used to update the policy model.
### Key Observations
* The pipeline emphasizes the use of language models for chess playing.
* The optional SFT stage suggests that supervised learning can improve the base model's performance.
* The GRPO loop highlights the reinforcement learning aspect of the training process.
* The diagram focuses on the interaction between the policy and reward models.
* The FEN string indicates a late-game scenario.
### Interpretation
This diagram represents a modern approach to training chess-playing agents, leveraging the power of large language models and reinforcement learning. The use of a base language model (Qwen/Llama) suggests an attempt to transfer knowledge from general language understanding to the specific domain of chess. The annotations and SFT stage aim to align the model's behavior with expert chess knowledge. The GRPO loop allows the agent to learn from its own experiences and improve its policy over time. The reward model acts as a critic, providing feedback to the policy model and guiding its learning process. The diagram suggests a focus on learning to evaluate chess positions and select optimal moves. The inclusion of the FEN string and legal moves provides concrete context for the training process. The optional SFT step indicates a flexible training approach, allowing for both supervised and reinforcement learning techniques to be combined.