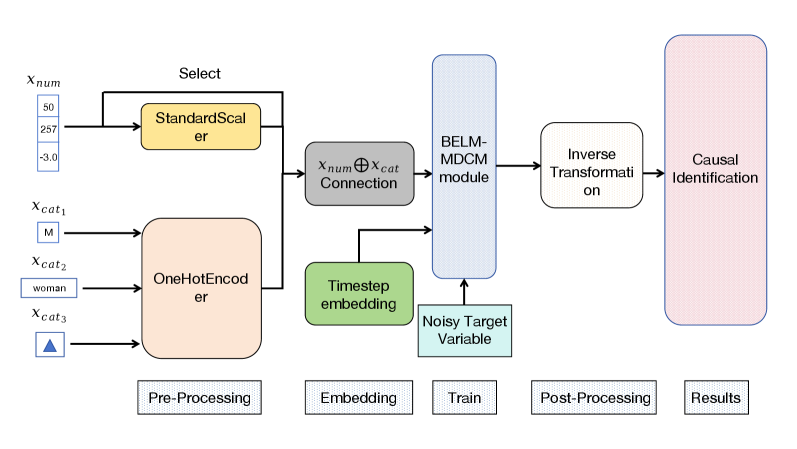
## Flowchart: Machine Learning Pipeline for Causal Identification
### Overview
The diagram illustrates a multi-stage machine learning pipeline for causal identification, structured into five phases: Pre-Processing, Embedding, Train, Post-Processing, and Results. The flow progresses left-to-right, with data transformations and model interactions depicted through interconnected blocks.
### Components/Axes
1. **Pre-Processing**
- **StandardScaler**: Standardizes numerical features (`x_num` values: 50, 257, -3.0).
- **OneHotEncoder**: Encodes categorical variables (`x_cat1`, `x_cat2`, `x_cat3` with labels: "M", "woman", and a triangle symbol).
2. **Embedding**
- **Timestep Embedding**: Processes temporal data.
- **Connection**: Combines standardized numerical (`x_num`) and encoded categorical (`x_cat`) features via a ⊕ (addition) operation.
3. **Train**
- **BELM-MDCM Module**: Trains on combined features to produce a **Noisy Target Variable**.
4. **Post-Processing**
- **Inverse Transformation**: Reverts scaled/encoded data to original space.
5. **Results**
- **Causal Identification**: Final output block.
### Detailed Analysis
- **Pre-Processing**:
- Numerical features (`x_num`) are standardized using `StandardScaler` (mean=0, std=1).
- Categorical variables (`x_cat1`, `x_cat2`, `x_cat3`) are one-hot encoded, with labels like "M" (gender), "woman" (occupation), and a triangle symbol (possibly a missing/unknown category).
- **Embedding**:
- Temporal data is embedded via `Timestep Embedding`, while numerical and categorical features are fused via element-wise addition (`x_num ⊕ x_cat`).
- **Train**:
- The **BELM-MDCM Module** (likely a hybrid model combining BERT-like language modeling with MDCM causal inference) processes the embedded data to predict a **Noisy Target Variable**.
- **Post-Processing**:
- **Inverse Transformation** undoes scaling/encoding to recover original feature scales.
- **Results**:
- **Causal Identification** block outputs the final causal relationships.
### Key Observations
1. **Data Flow**: Numerical and categorical features are preprocessed separately before being combined for training.
2. **Temporal Component**: The `Timestep Embedding` suggests time-series data is part of the input.
3. **Causal Focus**: The pipeline explicitly targets causal identification, implying the BELM-MDCM module is designed for counterfactual reasoning or causal effect estimation.
4. **Noisy Target**: The presence of a "Noisy Target Variable" indicates the model accounts for measurement error or confounding variables.
### Interpretation
This pipeline demonstrates a structured approach to causal inference in machine learning:
1. **Pre-Processing** ensures data quality by standardizing numerical features and encoding categorical variables.
2. **Embedding** integrates temporal dynamics, critical for time-dependent causal relationships.
3. **BELM-MDCM Module** likely combines deep learning (BELM) with causal modeling (MDCM) to handle complex interactions.
4. **Inverse Transformation** is essential for interpreting results in the original feature space, aiding causal interpretation.
5. The **Noisy Target Variable** suggests robustness to real-world data imperfections, a common challenge in causal analysis.
The diagram emphasizes a hybrid approach, merging statistical preprocessing, deep learning, and causal modeling to address complex, real-world datasets. The absence of explicit numerical results in the diagram implies this is a conceptual pipeline rather than an empirical study.