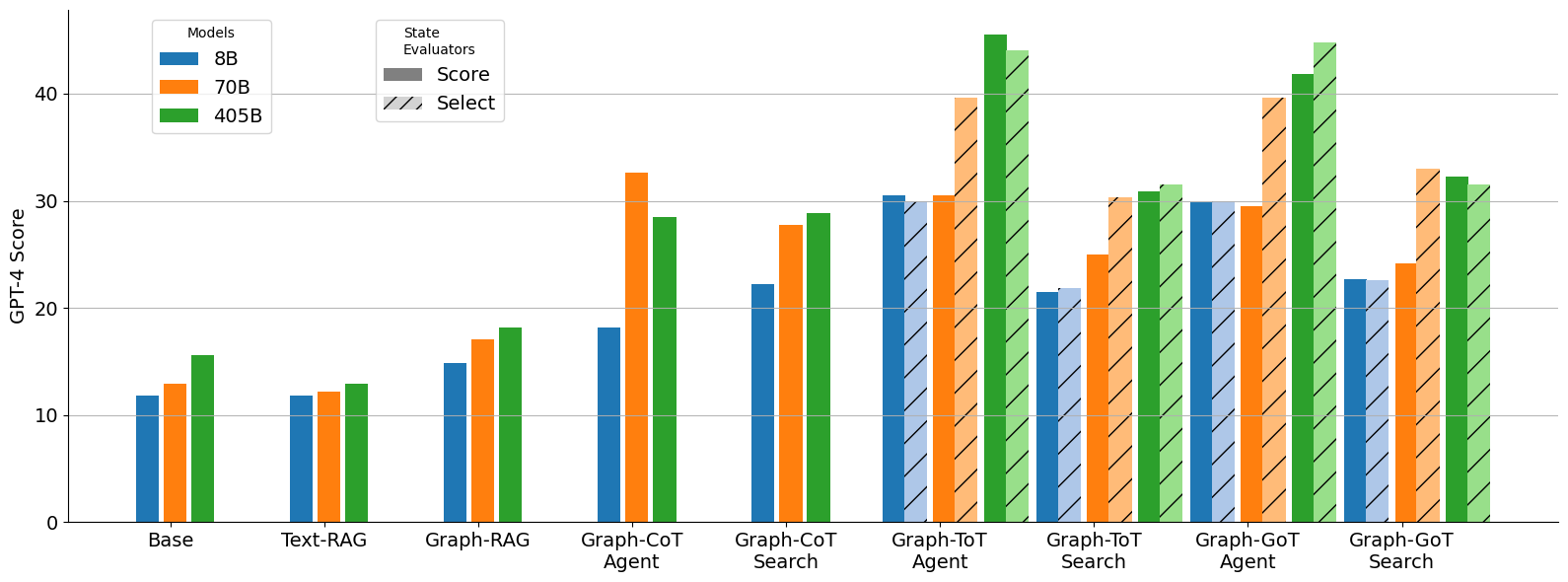
## Bar Chart: GPT-4 Scores Across Models and Evaluation Methods
### Overview
The chart compares GPT-4 scores (0–40) for three models (8B, 70B, 405B) across nine evaluation methods: Base, Text-RAG, Graph-RAG, Graph-CoT Agent, Graph-CoT Search, Graph-ToT Agent, Graph-ToT Search, Graph-GoT Agent, and Graph-GoT Search. The 405B model consistently outperforms the others, with the Graph-ToT and Graph-GoT methods showing the highest scores.
### Components/Axes
- **X-axis**: Evaluation methods (Base, Text-RAG, Graph-RAG, Graph-CoT Agent, Graph-CoT Search, Graph-ToT Agent, Graph-ToT Search, Graph-GoT Agent, Graph-GoT Search).
- **Y-axis**: GPT-4 Score (0–40).
- **Legend**:
- Blue: 8B model
- Orange: 70B model
- Green: 405B model
- **Spatial Grounding**:
- Legend: Top-left corner.
- X-axis labels: Bottom, centered under each evaluation method.
- Y-axis: Left, with ticks at 0, 10, 20, 30, 40.
### Detailed Analysis
- **Base**:
- 8B: ~12
- 70B: ~13
- 405B: ~15
- **Text-RAG**:
- 8B: ~12
- 70B: ~13
- 405B: ~14
- **Graph-RAG**:
- 8B: ~15
- 70B: ~17
- 405B: ~18
- **Graph-CoT Agent**:
- 8B: ~18
- 70B: ~22
- 405B: ~28
- **Graph-CoT Search**:
- 8B: ~22
- 70B: ~28
- 405B: ~29
- **Graph-ToT Agent**:
- 8B: ~30
- 70B: ~31
- 405B: ~45
- **Graph-ToT Search**:
- 8B: ~31
- 70B: ~30
- 405B: ~43
- **Graph-GoT Agent**:
- 8B: ~30
- 70B: ~31
- 405B: ~42
- **Graph-GoT Search**:
- 8B: ~23
- 70B: ~25
- 405B: ~32
### Key Observations
1. **Model Size Correlation**: The 405B model consistently scores highest across all methods, followed by 70B and 8B.
2. **Evaluation Method Impact**:
- Graph-ToT Agent/Search methods yield the highest scores (405B: ~43–45).
- Base and Text-RAG methods have the lowest scores (~12–15).
3. **Anomalies**:
- In Graph-GoT Search, the 405B model scores ~32, lower than its performance in other methods.
- The 70B model occasionally outperforms the 8B model but rarely surpasses the 405B.
### Interpretation
- **Model Size Matters**: Larger models (405B) demonstrate superior performance, suggesting that increased capacity enhances reasoning and task-solving.
- **Graph-ToT Methods Excel**: The Graph-ToT Agent/Search methods achieve the highest scores, indicating that combining graph-based reasoning with Tree of Thoughts (ToT) frameworks significantly improves outcomes.
- **Graph-GoT Search Exception**: The 405B model’s lower score in Graph-GoT Search (~32) may reflect method-specific limitations or data variability.
- **Practical Implications**: For high-stakes tasks, the 405B model with Graph-ToT methods is optimal. Smaller models (8B) are less effective, highlighting trade-offs between cost and performance.