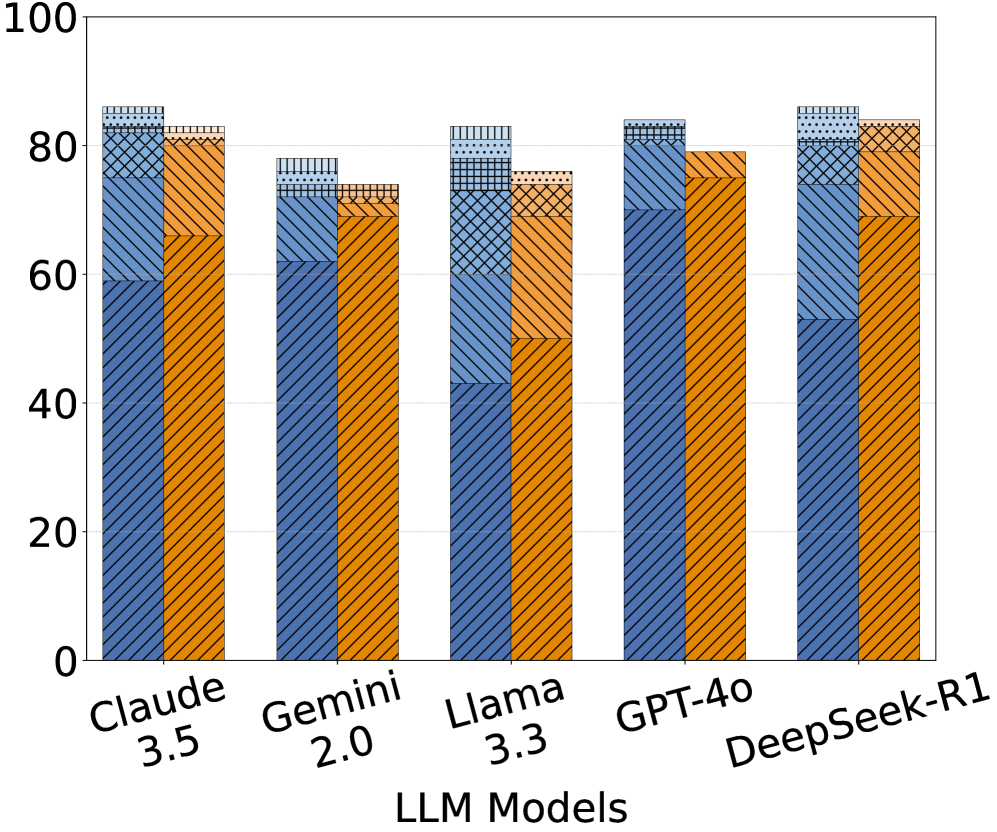
## Bar Chart: Performance Comparison of LLM Models on a Benchmark Task
### Overview
The chart compares the performance of five large language models (LLMs) across three categories: "Correct Answers," "Incorrect Answers," and "Uncertain Responses." Each model's performance is represented as a stacked bar, with segments differentiated by color and pattern. The y-axis measures performance as a percentage (0–100), while the x-axis lists the models: Claude 3.5, Gemini 2.0, Llama 3.3, GPT-4, and DeepSeek-R1.
### Components/Axes
- **X-Axis (Categories)**: LLM Models (Claude 3.5, Gemini 2.0, Llama 3.3, GPT-4, DeepSeek-R1).
- **Y-Axis (Scale)**: Percentage (0–100), with gridlines at 20% intervals.
- **Legend**:
- **Blue (Solid)**: Correct Answers.
- **Orange (Diagonal Hatch)**: Incorrect Answers.
- **Gray (Dotted)**: Uncertain Responses.
- **Bar Structure**: Stacked vertically, with segments ordered from bottom (Correct Answers) to top (Uncertain Responses).
### Detailed Analysis
1. **Claude 3.5**:
- Correct Answers: ~60% (blue).
- Incorrect Answers: ~20% (orange).
- Uncertain Responses: ~5% (gray).
2. **Gemini 2.0**:
- Correct Answers: ~65% (blue).
- Incorrect Answers: ~10% (orange).
- Uncertain Responses: ~10% (gray).
3. **Llama 3.3**:
- Correct Answers: ~45% (blue).
- Incorrect Answers: ~30% (orange).
- Uncertain Responses: ~10% (gray).
4. **GPT-4**:
- Correct Answers: ~70% (blue).
- Incorrect Answers: ~15% (orange).
- Uncertain Responses: ~5% (gray).
5. **DeepSeek-R1**:
- Correct Answers: ~55% (blue).
- Incorrect Answers: ~25% (orange).
- Uncertain Responses: ~10% (gray).
### Key Observations
- **Highest Correct Answers**: GPT-4 (~70%) and DeepSeek-R1 (~55%) lead in correct responses.
- **Lowest Correct Answers**: Llama 3.3 (~45%) underperforms in this category.
- **Highest Uncertainty**: Gemini 2.0 and DeepSeek-R1 tie at ~10% for uncertain responses.
- **Incorrect Answers**: Llama 3.3 (~30%) has the highest rate of incorrect answers, while GPT-4 (~15%) has the lowest.
### Interpretation
The data suggests significant variability in model reliability. GPT-4 demonstrates the strongest performance, with the highest correct answers and lowest uncertainty. Llama 3.3 struggles with accuracy, showing both the lowest correct answers and highest incorrect responses. Gemini 2.0 and DeepSeek-R1 exhibit moderate performance but share the highest uncertainty, potentially indicating limitations in confidence calibration. The patterns (e.g., GPT-4’s low uncertainty) may reflect architectural differences or training data quality. These trends highlight trade-offs between accuracy, confidence, and error rates across LLMs.