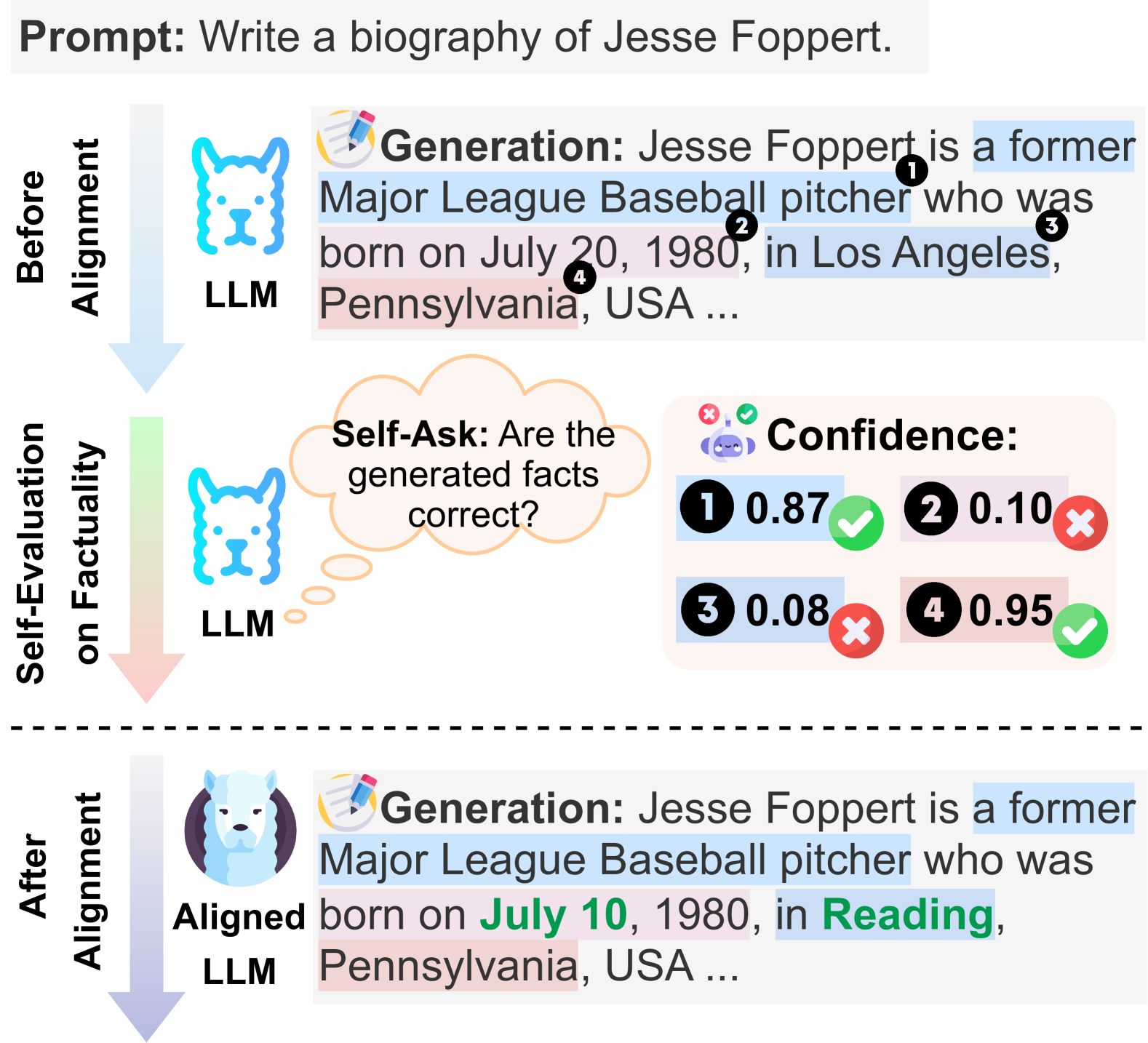
# Technical Document Extraction: LLM Factuality Alignment Process
This document describes a technical diagram illustrating the workflow for improving the factuality of a Large Language Model (LLM) through a self-evaluation and alignment process.
## 1. Header Section
* **Prompt:** "Write a biography of Jesse Foppert."
---
## 2. Main Process Flow (Pre-Alignment)
This section is divided into two vertical stages connected by a downward-pointing gradient arrow (blue to green to red).
### Stage 1: Before Alignment
* **Actor:** LLM (represented by a blue line-art dog icon).
* **Action:** **Generation**
* **Output Text:** "Jesse Foppert is a former Major League Baseball pitcher who was born on July 20, 1980, in Los Angeles, Pennsylvania, USA ..."
* **Annotated Claims:** Specific segments of the text are highlighted and numbered:
1. **[1]** "a former Major League Baseball pitcher" (Highlighted in blue)
2. **[2]** "July 20" (Highlighted in white/grey)
3. **[3]** "Los Angeles" (Highlighted in blue)
4. **[4]** "Pennsylvania" (Highlighted in red/pink)
### Stage 2: Self-Evaluation on Factuality
* **Actor:** LLM (same icon).
* **Internal Thought (Self-Ask):** "Are the generated facts correct?"
* **Component: Confidence Scores** (Located at the right):
* A panel displays confidence values for the four numbered claims from Stage 1:
* **1: 0.87** (Accompanied by a green checkmark icon)
* **2: 0.10** (Accompanied by a red 'X' icon)
* **3: 0.08** (Accompanied by a red 'X' icon)
* **4: 0.95** (Accompanied by a green checkmark icon)
---
## 3. Post-Alignment Section
Separated by a dashed horizontal line, this section shows the result after the alignment process.
### Stage 3: After Alignment
* **Actor:** Aligned LLM (represented by a detailed, colored white dog/wolf icon).
* **Action:** **Generation**
* **Output Text:** "Jesse Foppert is a former Major League Baseball pitcher who was born on **July 10**, 1980, in **Reading**, Pennsylvania, USA ..."
* **Key Changes and Trends:**
* The model has corrected the low-confidence facts identified in Stage 2.
* **Correction 1 (Date):** "July 20" (Claim 2, low confidence) has been changed to **July 10** (Text is bolded and green).
* **Correction 2 (City):** "Los Angeles" (Claim 3, low confidence) has been changed to **Reading** (Text is bolded and green).
* **Consistency:** "Pennsylvania" (Claim 4, high confidence) remains in the text, though the background highlight is now a light red/pink. "a former Major League Baseball pitcher" (Claim 1, high confidence) remains highlighted in blue.
---
## 4. Summary of Data Transformations
| Claim ID | Original Value (Before) | Confidence | Final Value (After) | Status |
| :--- | :--- | :--- | :--- | :--- |
| 1 | a former MLB pitcher | 0.87 | a former MLB pitcher | Retained |
| 2 | July 20 | 0.10 | **July 10** | **Corrected** |
| 3 | Los Angeles | 0.08 | **Reading** | **Corrected** |
| 4 | Pennsylvania | 0.95 | Pennsylvania | Retained |
**Technical Conclusion:** The diagram demonstrates a "Self-Ask" mechanism where an LLM evaluates its own generated claims. By identifying claims with low confidence scores (0.10 and 0.08), the "Aligned LLM" is able to regenerate the text, replacing the erroneous facts with corrected data while maintaining the high-confidence factual structure.