\n
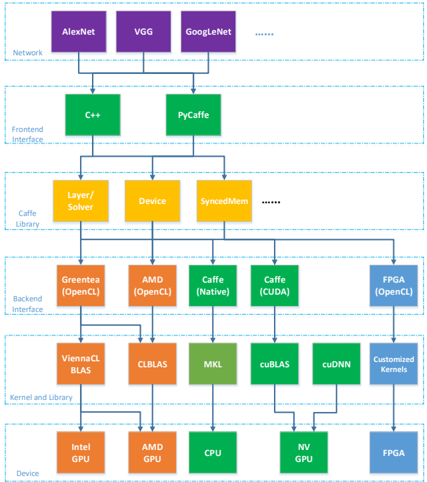
## Diagram: Caffe Deep Learning Framework Architecture
### Overview
This diagram illustrates the architecture of the Caffe deep learning framework, showing the flow of data and operations from the network level down to the device level. It depicts a layered structure with five main sections: Network, Frontend Interface, Caffe Library, Backend Interface, and Kernel/Build Library, culminating in the Device layer. The diagram uses color-coding to differentiate the components within each layer.
### Components/Axes
The diagram is structured into five horizontal layers, each representing a different level of abstraction:
1. **Network (Purple):** AlexNet, VGG, GoogleNet, and "..." indicating other networks.
2. **Frontend Interface (Orange):** C++, PyCaffe.
3. **Caffe Library (Yellow):** Layer/Solver, Device, SyncedMem, and "..." indicating other components.
4. **Backend Interface (Green):** Greentea (OpenCL), AMD (OpenCL), Caffe (Native), Caffe (CUDA), FPGA (OpenCL).
5. **Kernel/Build Library (Teal/Brown):** ViennaCL BLAS, CLBLAS, MKL, cuBLAS, cuDNN, Customized Kernels.
6. **Device (Various):** Intel GPU, AMD GPU, CPU, NV GPU, FPGA.
Arrows indicate the flow of data and dependencies between components.
### Detailed Analysis or Content Details
The diagram shows a hierarchical flow:
* **Network Layer:** Multiple network architectures (AlexNet, VGG, GoogleNet) feed into the Frontend Interface.
* **Frontend Interface Layer:** C++ and PyCaffe receive input from the Network layer.
* **Caffe Library Layer:** The Layer/Solver and Device components receive input from the Frontend Interface. SyncedMem is also present, with an ellipsis suggesting other components.
* **Backend Interface Layer:** Greentea (OpenCL), AMD (OpenCL), Caffe (Native), Caffe (CUDA), and FPGA (OpenCL) receive input from the Caffe Library.
* **Kernel/Build Library Layer:** ViennaCL BLAS, CLBLAS, MKL, cuBLAS, cuDNN, and Customized Kernels receive input from the Backend Interface.
* **Device Layer:** Intel GPU, AMD GPU, CPU, NV GPU, and FPGA receive input from the Kernel/Build Library.
The diagram illustrates that a single network architecture can be processed through multiple frontend interfaces, which then utilize the Caffe Library. The Caffe Library then leverages various backend interfaces and kernel libraries to execute operations on different devices.
### Key Observations
* The diagram highlights the flexibility of Caffe, allowing for the use of different network architectures, frontend interfaces, backend interfaces, and devices.
* The presence of both Caffe (Native) and Caffe (CUDA) in the Backend Interface suggests support for both CPU and GPU-based computation.
* The inclusion of FPGA (OpenCL) indicates support for hardware acceleration using Field-Programmable Gate Arrays.
* The "..." notations suggest that the diagram is not exhaustive and that there are other components and options available within each layer.
### Interpretation
The diagram demonstrates the modular and adaptable nature of the Caffe deep learning framework. It showcases how Caffe abstracts the underlying hardware and software complexities, allowing users to easily switch between different network architectures, programming languages (C++, Python), and computational devices (CPU, GPU, FPGA). This flexibility is a key strength of Caffe, enabling it to be deployed in a wide range of applications and environments. The layered architecture promotes code reusability and maintainability, while the support for multiple backends and devices allows for optimized performance based on the available hardware resources. The diagram effectively communicates the framework's design principles and its ability to cater to diverse computational needs. The inclusion of specialized libraries like cuDNN and ViennaCL BLAS indicates a focus on performance optimization for specific hardware platforms.