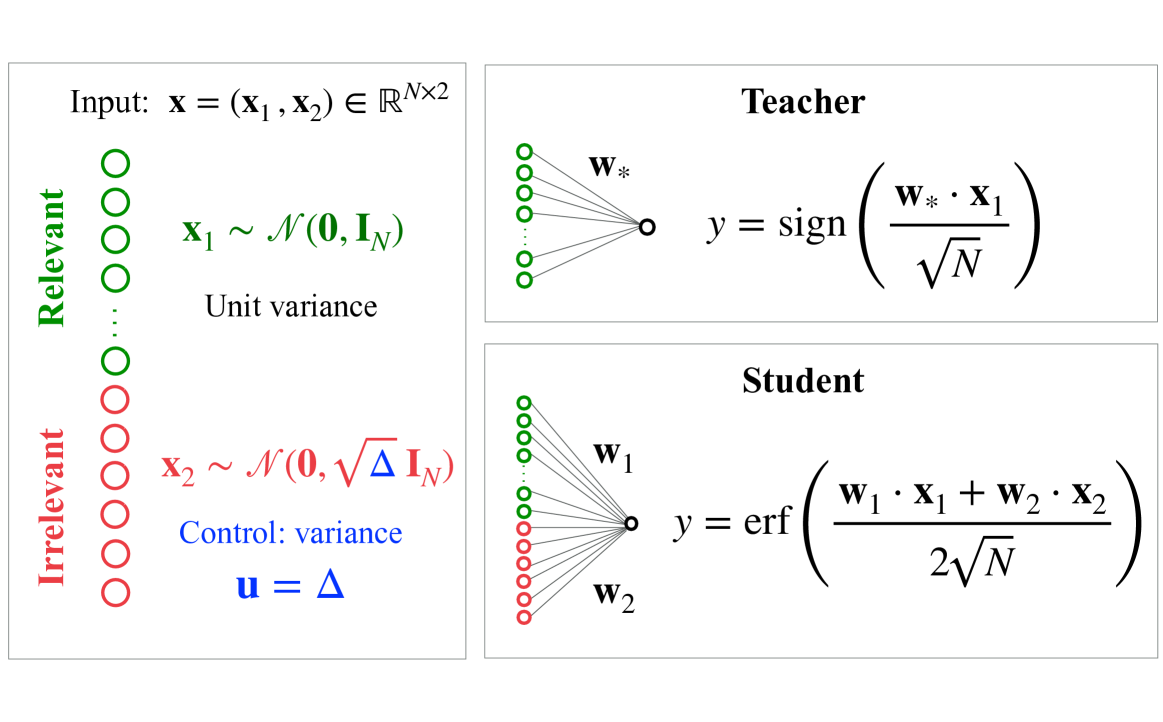
## Neural Network Diagram: Teacher-Student Model
### Overview
The image presents a diagram illustrating a teacher-student model in a neural network context. It describes the input data, the teacher network's output, and the student network's output. The diagram highlights the concept of relevant and irrelevant input features and their impact on the learning process.
### Components/Axes
* **Input:**
* `x = (x1, x2) ∈ R^(N x 2)`: The input vector `x` consists of two components, `x1` and `x2`, and belongs to the real space of dimension `N x 2`.
* **Relevant:** A vertical stack of green circles, labeled "Relevant" on the left. Represents the relevant input feature `x1`.
* `x1 ~ N(0, IN)`: `x1` follows a normal distribution with mean 0 and covariance matrix `IN` (identity matrix of size N).
* "Unit variance" is written below the equation.
* **Irrelevant:** A vertical stack of red circles, labeled "Irrelevant" on the left. Represents the irrelevant input feature `x2`.
* `x2 ~ N(0, √Δ IN)`: `x2` follows a normal distribution with mean 0 and covariance matrix `√Δ IN`.
* "Control: variance" is written below the equation.
* `u = Δ`: Control parameter `u` is equal to `Δ`.
* **Teacher:**
* A network with green input nodes connected to a single output node.
* `w*`: Represents the weights of the teacher network.
* `y = sign(w* · x1 / √N)`: The teacher's output `y` is the sign of the dot product of the teacher's weights `w*` and the relevant input `x1`, divided by the square root of `N`.
* **Student:**
* A network with green and red input nodes connected to a single output node.
* `w1`: Represents the weights associated with the relevant input `x1` in the student network.
* `w2`: Represents the weights associated with the irrelevant input `x2` in the student network.
* `y = erf((w1 · x1 + w2 · x2) / (2√N))`: The student's output `y` is the error function (erf) of the sum of the dot products of the student's weights `w1` and `w2` with the relevant input `x1` and irrelevant input `x2` respectively, divided by `2√N`.
### Detailed Analysis
* **Input Representation:** The input `x` is composed of two parts: a relevant feature `x1` and an irrelevant feature `x2`. The relevance is indicated by the color-coding (green for relevant, red for irrelevant).
* **Teacher Network:** The teacher network only uses the relevant input feature `x1` to produce its output. The output is a binary value (+1 or -1) determined by the sign function.
* **Student Network:** The student network uses both the relevant (`x1`) and irrelevant (`x2`) input features. The output is a continuous value determined by the error function.
* **Variance Control:** The variance of the irrelevant input feature `x2` is controlled by the parameter `Δ`. This allows for studying the effect of irrelevant information on the student's learning process.
### Key Observations
* The teacher network is designed to focus solely on the relevant input feature.
* The student network is exposed to both relevant and irrelevant features, potentially making the learning process more complex.
* The control parameter `Δ` allows for manipulating the amount of noise or irrelevant information the student network receives.
### Interpretation
The diagram illustrates a setup for studying how neural networks learn in the presence of irrelevant information. The teacher network represents an ideal learner that only focuses on the essential features. The student network, on the other hand, must learn to filter out the irrelevant information to achieve good performance. By varying the variance of the irrelevant input feature (`Δ`), one can investigate how the student's learning process is affected by the presence of noise or distracting information. This setup is useful for understanding the robustness and generalization capabilities of neural networks.