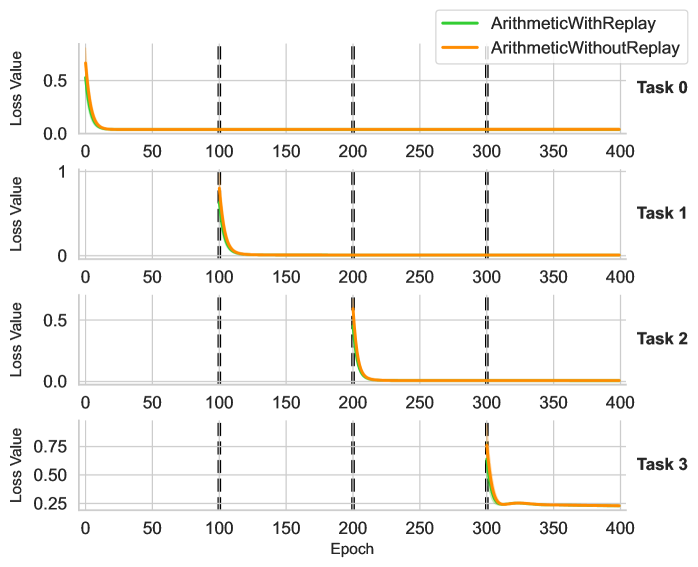
## Line Graph: Loss Value vs. Epoch Across Four Tasks
### Overview
The image displays four vertically stacked line graphs comparing the loss value convergence of two algorithms ("ArithmeticWithReplay" and "ArithmeticWithoutReplay") across four distinct tasks (Task 0–Task 3). Each graph tracks loss reduction over 400 training epochs, with vertical dashed lines marking key epoch intervals (100, 200, 300).
---
### Components/Axes
- **X-axis**: Epoch (0–400, linear scale)
- **Y-axis**: Loss Value (0–0.75, linear scale)
- **Legend**:
- Green line: ArithmeticWithReplay
- Orange line: ArithmeticWithoutReplay
- **Task Labels**: Task 0 (top), Task 1, Task 2, Task 3 (bottom)
- **Vertical Dashed Lines**: At 100, 200, and 300 epochs (consistent across all tasks)
---
### Detailed Analysis
#### Task 0
- **Green Line (WithReplay)**: Starts at ~0.5 loss, drops sharply to ~0.05 by 50 epochs, then plateaus.
- **Orange Line (WithoutReplay)**: Starts at ~0.5 loss, drops sharply to ~0.05 by 50 epochs, then plateaus. Slightly higher loss than green line after 100 epochs.
#### Task 1
- **Green Line**: Starts at ~0.5 loss, drops to ~0.05 by 100 epochs, then plateaus.
- **Orange Line**: Starts at ~0.5 loss, drops to ~0.05 by 100 epochs, then plateaus. Slightly higher loss than green line after 100 epochs.
#### Task 2
- **Green Line**: Starts at ~0.5 loss, drops to ~0.05 by 150 epochs, then plateaus.
- **Orange Line**: Starts at ~0.5 loss, drops to ~0.05 by 150 epochs, then plateaus. Slightly higher loss than green line after 150 epochs.
#### Task 3
- **Green Line**: Starts at ~0.75 loss, drops sharply to ~0.05 by 300 epochs, then plateaus.
- **Orange Line**: Starts at ~0.75 loss, drops sharply to ~0.05 by 300 epochs, then plateaus. Slightly higher loss than green line after 300 epochs.
---
### Key Observations
1. **Consistent Performance Gap**: The "WithReplay" algorithm (green) consistently achieves lower loss values than "WithoutReplay" (orange) across all tasks, with the gap widening in later epochs.
2. **Task-Specific Convergence**:
- Tasks 0–2 show faster convergence (within 50–150 epochs).
- Task 3 requires significantly more epochs (300) to reach stable loss.
3. **Vertical Line Alignment**: All tasks exhibit similar convergence patterns relative to the 100/200/300 epoch markers, suggesting these intervals may represent evaluation checkpoints.
---
### Interpretation
The data demonstrates that the "ArithmeticWithReplay" algorithm outperforms "ArithmeticWithoutReplay" in retaining learned knowledge across tasks, as evidenced by consistently lower loss values. The vertical dashed lines likely indicate milestones where the model's performance is assessed, with Task 3 requiring the longest training to stabilize. This suggests that replay mechanisms mitigate catastrophic forgetting in multi-task learning scenarios, particularly for complex tasks (e.g., Task 3). The uniform trend across tasks implies the replay method generalizes well, though Task 3's higher initial loss may reflect greater inherent complexity.