\n
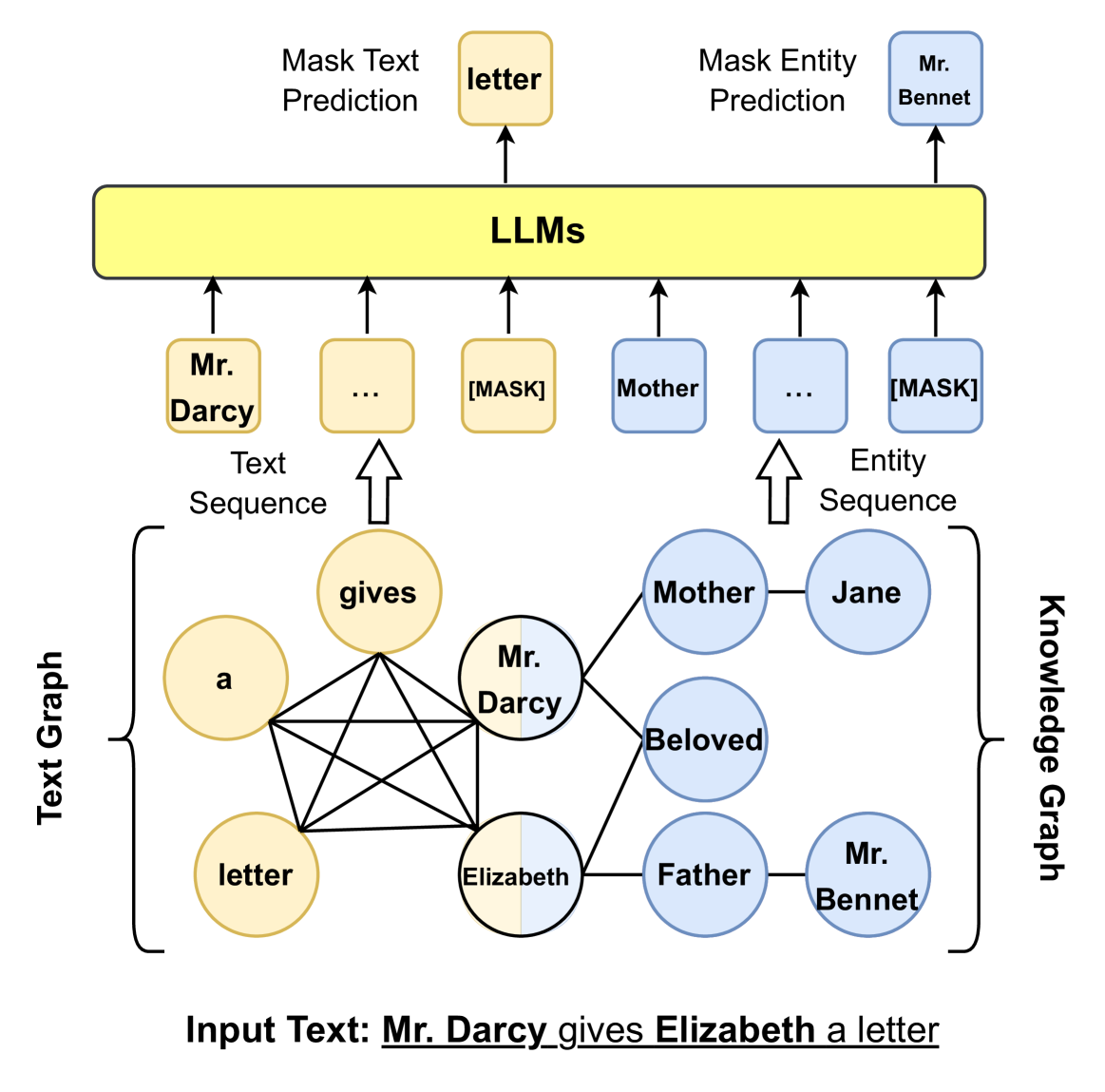
## Diagram: LLM Processing of Text and Knowledge Graphs
### Overview
This diagram illustrates how Large Language Models (LLMs) process text and knowledge graphs, specifically focusing on masked text and entity prediction. It depicts two parallel processing paths: one using a text sequence and the other using an entity sequence, both derived from an input text. The diagram highlights the use of masking for prediction tasks.
### Components/Axes
The diagram consists of the following components:
* **Input Text:** "Mr. Darcy gives Elizabeth a letter" (located at the bottom center).
* **Text Graph:** A graph representation of the input text, showing relationships between words. (Left side)
* **Knowledge Graph:** A graph representation of entities and their relationships. (Right side)
* **LLMs:** A central block representing Large Language Models. (Center)
* **Mask Text Prediction:** A process within the LLM that predicts masked words. (Top-left)
* **Mask Entity Prediction:** A process within the LLM that predicts masked entities. (Top-right)
* **Text Sequence:** A sequence of words fed into the LLM. (Below "Mask Text Prediction")
* **Entity Sequence:** A sequence of entities fed into the LLM. (Below "Mask Entity Prediction")
### Detailed Analysis or Content Details
**Input Text:** The input text is "Mr. Darcy gives Elizabeth a letter".
**Text Graph:**
* Nodes: "a", "letter", "gives", "Mr. Darcy", "Elizabeth".
* Edges:
* "a" connects to "letter".
* "letter" connects to "gives".
* "gives" connects to "Mr. Darcy" and "Elizabeth".
* "Mr. Darcy" connects to "Elizabeth".
* "Elizabeth" connects to "letter".
**Knowledge Graph:**
* Nodes: "Mother", "Jane", "Mr. Bennet", "Father", "Beloved", "Mr. Darcy", "Elizabeth".
* Edges:
* "Mother" connects to "Jane".
* "Beloved" connects to "Mr. Darcy" and "Elizabeth".
* "Father" connects to "Elizabeth" and "Mr. Bennet".
* "Mr. Bennet" connects to "Elizabeth".
**LLM Processing:**
* **Mask Text Prediction:** The LLM receives a text sequence with a "[MASK]" token. The prediction is "letter".
* **Mask Entity Prediction:** The LLM receives an entity sequence with a "[MASK]" token. The prediction is "Mr. Bennet".
* **Text Sequence:** Shows "Mr. Darcy" followed by "..." and then "[MASK]".
* **Entity Sequence:** Shows "Mother" followed by "..." and then "[MASK]".
### Key Observations
* The diagram illustrates a parallel processing approach, handling both textual and entity-based information.
* Masking is used as a technique for prediction in both text and entity sequences.
* The knowledge graph represents relationships between entities, while the text graph represents relationships between words.
* The LLM acts as a central processing unit, receiving input from both graphs and generating predictions.
### Interpretation
The diagram demonstrates a method for leveraging LLMs to understand and reason about text by representing it in both textual and knowledge graph formats. The use of masking suggests a cloze-style prediction task, where the LLM is challenged to fill in missing information. This approach allows the LLM to utilize contextual information from both the text itself and the underlying knowledge graph to make more accurate predictions. The parallel processing of text and entities suggests that the system is designed to capture both linguistic and semantic relationships within the input text. The diagram highlights a potential architecture for building more sophisticated natural language understanding systems. The choice of "Pride and Prejudice" characters suggests a focus on relational understanding and character interactions.