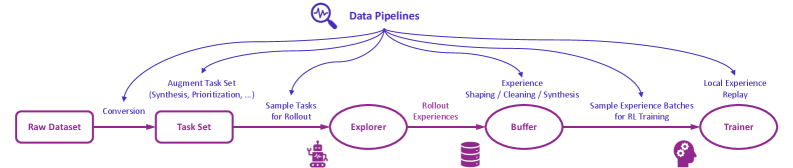
## Diagram: Data Pipelines Flowchart
### Overview
The image displays a flowchart titled "Data Pipelines," illustrating the sequential and cyclical process of data flow in a machine learning or reinforcement learning (RL) training system. The diagram uses a left-to-right flow with a feedback loop, connecting various processing stages represented by rounded rectangles and ovals, annotated with descriptive labels and icons.
### Components/Axes
* **Title:** "Data Pipelines" (top-center, accompanied by a magnifying glass icon).
* **Primary Flow Nodes (from left to right):**
1. `Raw Dataset` (rounded rectangle, far left).
2. `Task Set` (rounded rectangle).
3. `Explorer` (oval, with a small robot/character icon to its lower-left).
4. `Buffer` (oval, with a database/cylinder icon below it).
5. `Trainer` (oval, far right, with a gear/settings icon to its lower-left).
* **Connecting Arrows & Process Labels:**
* Arrow from `Raw Dataset` to `Task Set`: Labeled **"Conversion"**.
* Arrow from `Task Set` to `Explorer`: Labeled **"Sample Tasks for Rollout"**.
* Arrow from `Explorer` to `Buffer`: Labeled **"Rollout Experiences"**.
* Arrow from `Buffer` to `Trainer`: Labeled **"Sample Experience Batches for RL Training"**.
* Arrow from `Trainer` looping back to `Buffer`: Labeled **"Local Experience Replay"**.
* **Additional Annotations:**
* Text above the `Raw Dataset` to `Task Set` arrow: **"Augment Task Set (Synthesis, Prioritization, ...)"**.
### Detailed Analysis
The diagram outlines a five-stage pipeline for processing data to train a reinforcement learning agent:
1. **Data Ingestion & Preparation:** The process begins with a `Raw Dataset`. This data undergoes **"Conversion"** to become a structured `Task Set`. This stage is enhanced by an external process to **"Augment Task Set"**, with examples given as **"(Synthesis, Prioritization, ...)"**.
2. **Task Execution & Experience Generation:** Specific tasks are selected from the `Task Set` via **"Sample Tasks for Rollout"** and passed to the `Explorer` component. The `Explorer` (likely an agent or policy) interacts with the environment, generating **"Rollout Experiences"**.
3. **Experience Storage:** The generated experiences are stored in a `Buffer`, which acts as a replay memory.
4. **Training:** The `Trainer` component retrieves data by **"Sample Experience Batches for RL Training"** from the `Buffer` to update the learning model.
5. **Feedback Loop:** A critical cyclical element is shown where the `Trainer` sends **"Local Experience Replay"** back to the `Buffer`, indicating that newly generated or processed experiences from the training phase are fed back into the memory for future sampling.
### Key Observations
* **Cyclical Nature:** The pipeline is not strictly linear; the "Local Experience Replay" arrow creates a closed loop between the `Trainer` and `Buffer`, emphasizing continuous learning and experience reuse.
* **Component Specialization:** Each node has a distinct role: storage (`Raw Dataset`, `Buffer`), structuring (`Task Set`), acting (`Explorer`), and learning (`Trainer`).
* **Augmentation Point:** The "Augment Task Set" process is highlighted as an external input that enriches the task generation phase, suggesting importance in curriculum learning or task prioritization.
* **Iconography:** Simple icons (magnifying glass, robot, database, gear) provide visual cues for the function of each component (search/analysis, agent, storage, configuration/training).
### Interpretation
This diagram represents a standard architecture for data-driven reinforcement learning systems. It visually explains how raw data is transformed into actionable tasks, how an agent generates experiential data through interaction, and how that data is stored and utilized for training. The inclusion of a feedback loop (`Local Experience Replay`) is a key design pattern in RL (like in algorithms such as DQN) to improve sample efficiency and stabilize learning by breaking temporal correlations in sequential data. The "Augment Task Set" step suggests an advanced pipeline where tasks are not just sampled but actively curated or generated to guide the learning process effectively. The entire flow emphasizes the transformation of static data (`Raw Dataset`) into dynamic, learning-generating experiences (`Rollout Experiences`) that are continuously recycled to improve the agent's policy.