## Line Chart: Lichess Puzzle Accuracy vs. Training Step for Two Models
### Overview
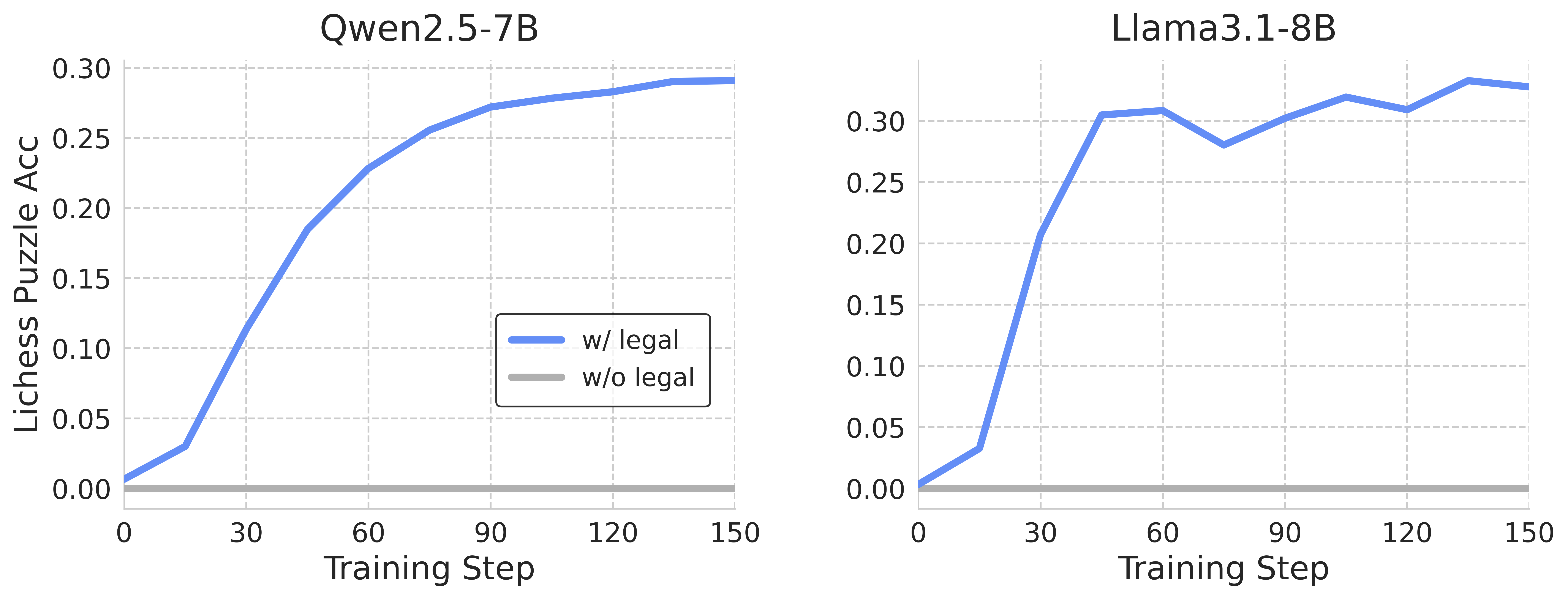
The image presents two line charts comparing the performance of two language models, Qwen2.5-7B and Llama3.1-8B, on Lichess puzzles during training. The charts plot "Lichess Puzzle Acc" (Accuracy) on the y-axis against "Training Step" on the x-axis. Each chart displays two lines representing performance "w/ legal" (with legal moves considered) and "w/o legal" (without legal moves considered).
### Components/Axes
* **X-axis:** "Training Step" ranging from 0 to 150. The axis is divided into increments of 30.
* **Y-axis:** "Lichess Puzzle Acc" (Accuracy) ranging from 0.00 to 0.30, divided into increments of 0.05.
* **Left Chart Title:** "Qwen2.5-7B"
* **Right Chart Title:** "Llama3.1-8B"
* **Legend (Left Chart):**
* Blue Line: "w/ legal"
* Gray Line: "w/o legal"
* **Legend (Right Chart):**
* Blue Line: "w/ legal"
* Gray Line: "w/o legal"
* **Gridlines:** Light gray vertical and horizontal gridlines are present in both charts.
### Detailed Analysis or Content Details
**Qwen2.5-7B (Left Chart):**
* **"w/ legal" (Blue Line):** The line starts at approximately 0.01 at Training Step 0. It exhibits a steep upward slope until approximately Training Step 60, reaching around 0.26. The slope then gradually decreases, leveling off around 0.29-0.30 between Training Steps 90 and 150.
* **"w/o legal" (Gray Line):** The line starts at approximately 0.01 at Training Step 0. It rises more slowly than the "w/ legal" line, reaching around 0.15 at Training Step 60. It continues to increase, but at a slower rate, reaching approximately 0.22 at Training Step 150.
**Llama3.1-8B (Right Chart):**
* **"w/ legal" (Blue Line):** The line starts at approximately 0.01 at Training Step 0. It rises rapidly, reaching around 0.28 at Training Step 30. It then plateaus around 0.30-0.32 between Training Steps 60 and 120, with some fluctuations. It decreases slightly to around 0.30 at Training Step 150.
* **"w/o legal" (Gray Line):** The line starts at approximately 0.01 at Training Step 0. It rises quickly, reaching around 0.20 at Training Step 30. It then increases more gradually, reaching approximately 0.27 at Training Step 60. It fluctuates between approximately 0.27 and 0.31 between Training Steps 60 and 150.
### Key Observations
* Both models show a clear positive correlation between training steps and Lichess puzzle accuracy.
* For both models, performance "w/ legal" consistently outperforms performance "w/o legal" throughout the training process.
* Llama3.1-8B reaches a higher peak accuracy than Qwen2.5-7B.
* Llama3.1-8B appears to converge faster than Qwen2.5-7B, reaching a plateau in accuracy earlier in the training process.
* Qwen2.5-7B shows a more gradual increase in accuracy over the entire training period.
### Interpretation
The data suggests that both Qwen2.5-7B and Llama3.1-8B are capable of learning to solve Lichess puzzles through training. The consistent outperformance of the "w/ legal" condition indicates that incorporating legal move constraints significantly improves the models' ability to solve puzzles correctly. The faster convergence and higher peak accuracy of Llama3.1-8B suggest that it may be a more efficient and effective model for this task, or that it benefits more from the legal move constraints. The plateauing of accuracy in both models after a certain number of training steps suggests that further training may yield diminishing returns. The fluctuations in the Llama3.1-8B "w/ legal" line between 60 and 150 training steps could indicate instability or sensitivity to the training data during that period. The difference in the learning curves between the two models could be attributed to differences in model architecture, training data, or hyperparameters.