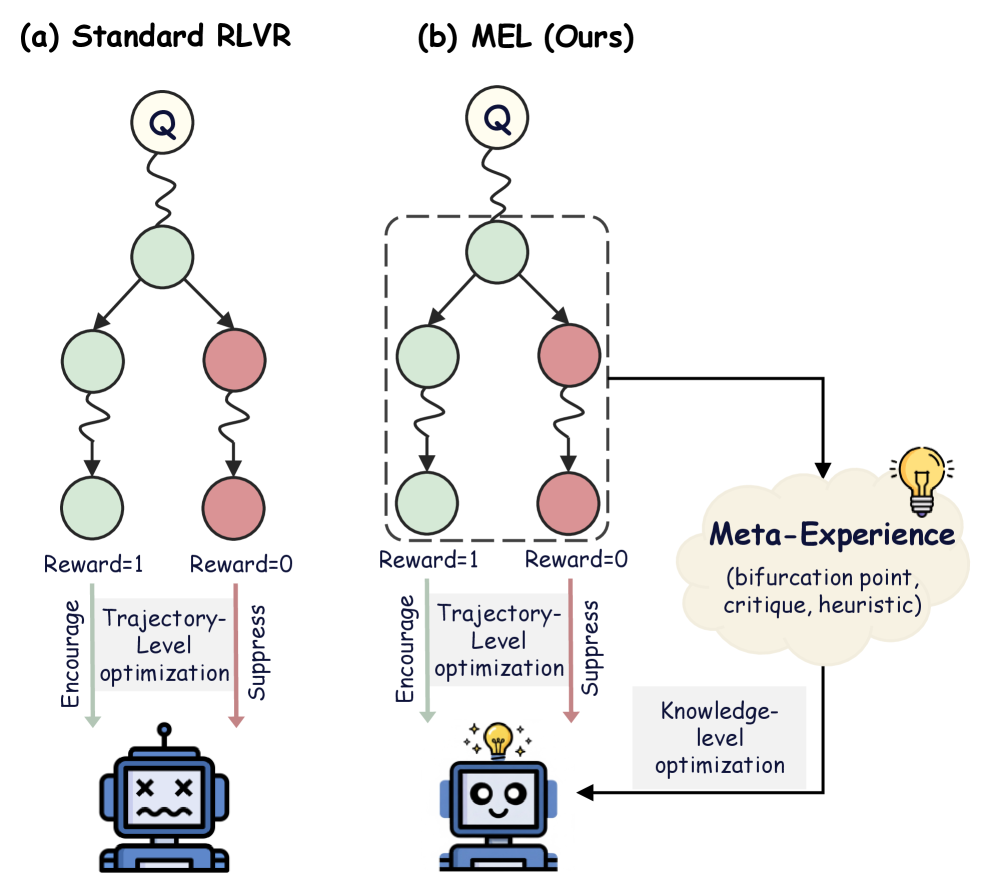
## Diagram: Comparison of Standard RLVR and MEL (Meta-Experience Learning) Architectures
### Overview
The image is a technical diagram comparing two reinforcement learning or decision-making architectures. On the left is "(a) Standard RLVR" and on the right is "(b) MEL (Ours)". The diagram illustrates how the proposed MEL method incorporates a "Meta-Experience" component to achieve "Knowledge-level optimization," leading to a more successful outcome compared to the standard "Trajectory-Level optimization" approach.
### Components/Axes
The diagram is divided into two primary vertical panels.
**Panel (a) - Standard RLVR (Left Side):**
* **Top:** A circled "Q" (likely representing a Query or Question) connects via a wavy line to a central green node.
* **Middle:** The central green node branches into two paths:
* Left Path: A green node leads to another green node via a wavy line.
* Right Path: A red node leads to another red node via a wavy line.
* **Reward Labels:** Below the terminal nodes are the labels "Reward=1" (under the green path) and "Reward=0" (under the red path).
* **Optimization Block:** A gray box labeled "Trajectory-Level optimization" sits below the reward labels.
* **Action Arrows:** Two arrows point downward from the optimization block:
* A green arrow labeled "Encourage" points to the left.
* A red arrow labeled "Suppress" points to the right.
* **Outcome Icon:** Both arrows point to a single robot icon at the bottom. The robot has "X" eyes and a wavy mouth, indicating a failed, confused, or negative state.
**Panel (b) - MEL (Ours) (Right Side):**
* **Top:** Identical starting structure to panel (a): a circled "Q" connects to a central green node.
* **Middle:** The central green node branches into two paths, identical to panel (a), but this entire branching structure is enclosed within a **dashed rectangular box**.
* **Reward Labels:** Identical to panel (a): "Reward=1" (left) and "Reward=0" (right).
* **Optimization Block:** An identical gray box labeled "Trajectory-Level optimization" sits below the reward labels, with identical "Encourage" (green) and "Suppress" (red) arrows.
* **Meta-Experience Component:** A key differentiating element. A black arrow originates from the **dashed box** and points to a cloud-shaped element on the right.
* The cloud is labeled "**Meta-Experience**" in bold, dark blue text.
* Inside the cloud, in smaller text: "(bifurcation point, critique, heuristic)".
* A yellow lightbulb icon is attached to the top-right of the cloud.
* **Knowledge Flow:** A black arrow leads from the "Meta-Experience" cloud down to a gray box labeled "**Knowledge-level optimization**".
* **Outcome Icon:** An arrow from the "Knowledge-level optimization" box points to a robot icon at the bottom. This robot has a smiling face and a glowing yellow lightbulb above its head, indicating a successful, enlightened, or positive state.
### Detailed Analysis
The diagram presents a flowchart-style comparison of two processes.
1. **Shared Initial Process:** Both methods start with a query (Q) leading to a decision point (central green node) that bifurcates into two possible trajectories: a "good" one (green nodes, Reward=1) and a "bad" one (red nodes, Reward=0).
2. **Standard RLVR Process:** The system applies "Trajectory-Level optimization" based on the final reward. It encourages the entire trajectory that led to Reward=1 and suppresses the one that led to Reward=0. The outcome is a single, negatively-valenced robot state, suggesting this method may lead to suboptimal or brittle learning.
3. **MEL Process:** The system performs the same trajectory-level optimization. However, it **additionally** extracts abstract knowledge from the decision point itself (the bifurcation within the dashed box). This extracted "Meta-Experience" consists of understanding the bifurcation point, forming critiques, and deriving heuristics. This meta-knowledge is then used for "Knowledge-level optimization," which directly informs and improves the agent, resulting in a positive, "enlightened" outcome.
### Key Observations
* **Spatial Grounding:** The "Meta-Experience" cloud is positioned to the right of the main flow in panel (b), connected directly to the decision-making core (the dashed box). The "Knowledge-level optimization" box is positioned between the cloud and the final robot icon.
* **Visual Metaphors:** The robot icons are critical visual cues. The "X" eyes in (a) denote failure or a dead end. The smiling face and lightbulb in (b) denote success and insight.
* **Color Coding:** Green consistently represents successful/rewarded paths and actions ("Encourage"). Red represents unsuccessful/unrewarded paths and actions ("Suppress"). Yellow is used for the lightbulb, symbolizing ideas and insight.
* **Structural Emphasis:** The dashed box in (b) highlights the specific component (the bifurcation event) that is being analyzed to generate meta-experience, which is absent in (a).
### Interpretation
This diagram argues that standard reinforcement learning from verification rewards (RLVR) operates only at the level of individual trajectories—optimizing based on final success or failure. This can be inefficient or lead to poor generalization.
The proposed **MEL (Meta-Experience Learning)** framework introduces a crucial **meta-cognitive layer**. Instead of just learning *what* to do (trajectory optimization), it learns *from the structure of the decision itself* (knowledge-level optimization). By analyzing bifurcation points—where a choice leads to vastly different outcomes—the system can extract generalizable critiques and heuristics. This "meta-experience" allows the agent to build a more robust, abstract understanding of the problem space, leading to better performance and more "enlightened" behavior, as symbolized by the happy, illuminated robot. The core innovation is shifting learning from mere outcome-based reinforcement to insight-based knowledge formation.