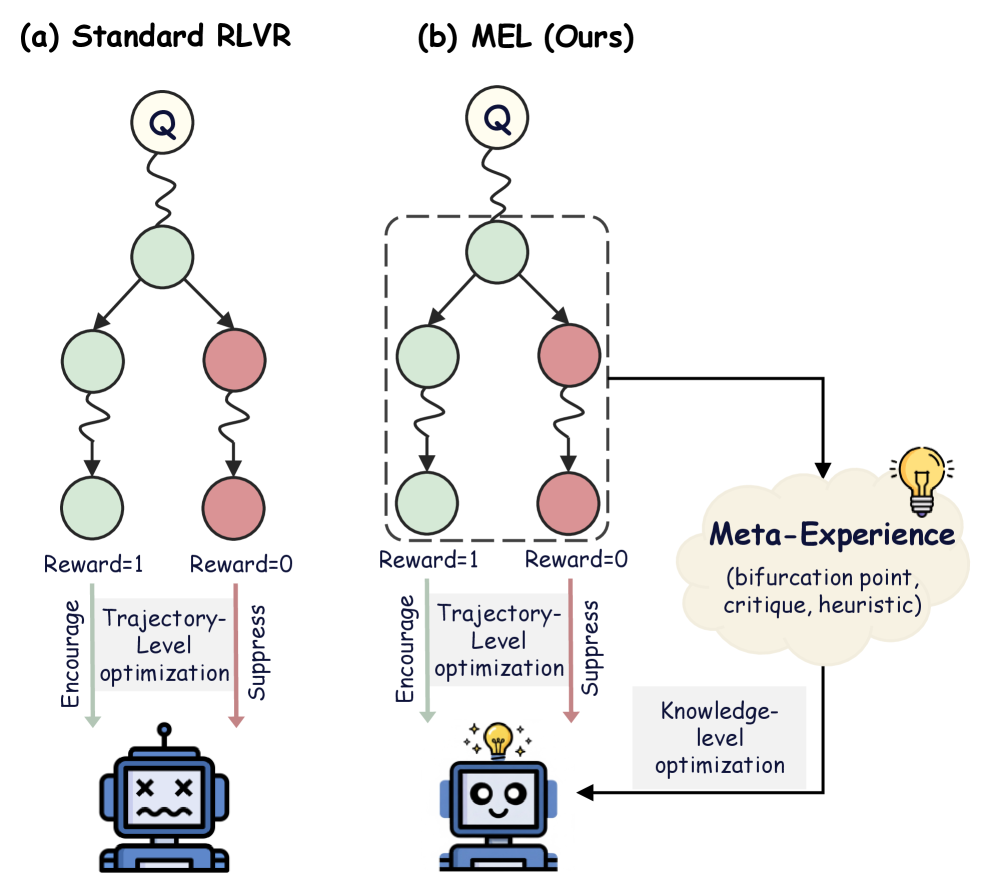
## Diagram: Comparison of Standard RLVR vs. MEL (Ours) Reinforcement Learning Architectures
### Overview
The image compares two reinforcement learning (RL) architectures:
- **(a) Standard RLVR**: A linear decision tree with reward-based feedback (Reward=1/0) and trajectory-level optimization.
- **(b) MEL (Ours)**: A modified architecture with bifurcation points, meta-experience integration, and knowledge-level optimization.
### Components/Axes
1. **Nodes**:
- **Green circles**: Represent states/actions with Reward=1.
- **Red circles**: Represent states/actions with Reward=0.
- **Dashed box**: Highlights a bifurcation point in MEL.
2. **Arrows**:
- **Solid arrows**: Indicate encouragement of trajectory-level optimization (green).
- **Dashed arrows**: Indicate suppression of trajectory-level optimization (red).
- **Dotted arrow**: Connects MEL to "Meta-Experience" (yellow cloud).
3. **Icons**:
- **Robot (a)**: Frowning face with X marks (failure state).
- **Robot (b)**: Smiling face with a lightbulb (success/insight state).
4. **Text Labels**:
- **Standard RLVR (a)**:
- "Encourage Trajectory-Level optimization" (green arrow).
- "Suppress Trajectory-Level optimization" (red arrow).
- **MEL (b)**:
- "Encourage Trajectory-Level optimization" (green arrow).
- "Suppress Trajectory-Level optimization" (red arrow).
- "Meta-Experience (bifurcation point, critique, heuristic)" (yellow cloud).
- "Knowledge-level optimization" (arrow from cloud to robot).
### Detailed Analysis
- **Standard RLVR (a)**:
- Linear flow: Question (Q) → State/Action → Reward feedback (1/0).
- Direct encouragement/suppression of trajectory-level optimization based on rewards.
- Robot icon reflects failure (X marks, sad face).
- **MEL (b)**:
- Bifurcation point introduces meta-experience (critique, heuristic).
- Dotted arrow links meta-experience to knowledge-level optimization.
- Robot icon reflects success (smile, lightbulb).
### Key Observations
1. **Bifurcation in MEL**: The dashed box in (b) introduces a decision point absent in (a), enabling adaptive feedback.
2. **Meta-Experience**: Explicitly modeled in MEL, integrating critique and heuristic reasoning for optimization.
3. **Reward Handling**: Both architectures use Reward=1/0, but MEL adds meta-experience to refine optimization.
4. **Robot Symbolism**: Visual contrast between failure (a) and success (b) emphasizes MEL’s improved outcomes.
### Interpretation
The diagram illustrates how MEL enhances Standard RLVR by:
1. **Incorporating Meta-Experience**: The yellow cloud represents higher-level reasoning (bifurcation, critique, heuristic), enabling the system to learn from past experiences rather than relying solely on immediate rewards.
2. **Knowledge-Level Optimization**: The dotted arrow suggests that meta-experience informs broader, systemic improvements beyond trajectory-specific adjustments.
3. **Adaptive Suppression**: The dashed red arrow in (b) implies dynamic suppression of suboptimal trajectories, guided by meta-experience.
This architecture addresses the limitations of Standard RLVR by introducing hierarchical learning, where meta-experience acts as a feedback loop to refine both trajectory and knowledge-level decisions. The robot icons symbolize the practical outcomes: MEL achieves success through integrated reasoning, while Standard RLVR remains constrained by linear, reward-driven optimization.