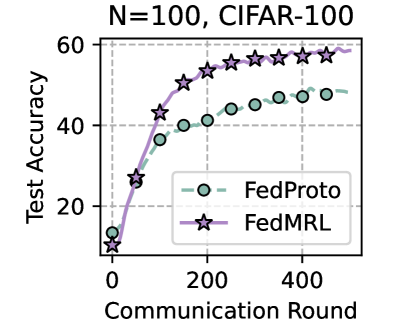
## Line Chart: Federated Learning Performance on CIFAR-100
### Overview
The image is a line chart comparing the test accuracy of two federated learning algorithms, FedProto and FedMRL, over a series of communication rounds. The chart is titled "N=100, CIFAR-100," indicating the experiment was conducted with 100 clients on the CIFAR-100 image classification dataset.
### Components/Axes
* **Title:** "N=100, CIFAR-100" (Top center)
* **Y-Axis:** Labeled "Test Accuracy". The scale runs from 0 to 60, with major tick marks and grid lines at intervals of 20 (0, 20, 40, 60).
* **X-Axis:** Labeled "Communication Round". The scale runs from 0 to approximately 500, with major labeled tick marks at 0, 200, and 400.
* **Legend:** Positioned in the bottom-right quadrant of the chart area.
* **FedProto:** Represented by a dashed green line with circular markers (○).
* **FedMRL:** Represented by a solid purple line with star-shaped markers (☆).
* **Grid:** A light gray grid is present, aligned with the major ticks on both axes.
### Detailed Analysis
**Data Series & Trends:**
1. **FedProto (Green line, circle markers):**
* **Trend:** Shows a steady, logarithmic-style increase. It rises quickly in the initial rounds and then continues to improve at a gradually decreasing rate.
* **Approximate Data Points:**
* Round 0: ~10% accuracy
* Round 100: ~35% accuracy
* Round 200: ~40% accuracy
* Round 300: ~45% accuracy
* Round 400: ~48% accuracy
* Final Point (~Round 480): ~49% accuracy
2. **FedMRL (Purple line, star markers):**
* **Trend:** Shows a steeper initial ascent compared to FedProto, followed by a strong, sustained increase that plateaus at a higher level. It consistently outperforms FedProto after the first few rounds.
* **Approximate Data Points:**
* Round 0: ~5% accuracy (lower starting point than FedProto)
* Round 100: ~50% accuracy
* Round 200: ~55% accuracy
* Round 300: ~58% accuracy
* Round 400: ~59% accuracy
* Final Point (~Round 480): ~60% accuracy
### Key Observations
* **Performance Gap:** FedMRL achieves a significantly higher final test accuracy (~60%) compared to FedProto (~49%).
* **Convergence Speed:** FedMRL not only reaches a higher accuracy but also converges to a high-performance region faster. By round 100, FedMRL (~50%) has already surpassed the final accuracy of FedProto.
* **Initial Conditions:** FedProto starts with a higher accuracy at round 0 (~10% vs. ~5%), but this advantage is quickly overtaken by FedMRL's superior learning trajectory.
* **Plateau Behavior:** Both curves show signs of plateauing towards the end of the plotted rounds, but FedMRL's plateau is at a substantially higher accuracy level.
### Interpretation
This chart demonstrates the comparative effectiveness of two federated learning algorithms on a standard image classification task (CIFAR-100) with a large client population (N=100). The data suggests that the **FedMRL algorithm is substantially more efficient and effective** than FedProto in this setting.
* **Why it matters:** In federated learning, communication rounds are a primary cost. An algorithm that achieves higher accuracy in fewer rounds (like FedMRL here) is highly desirable as it reduces communication overhead and training time.
* **Reading between the lines:** The steeper initial slope of FedMRL indicates it may have a better mechanism for aggregating knowledge from diverse clients early in the process. The persistent gap suggests its final model generalizes better to the test set. The experiment likely aims to showcase FedMRL as a state-of-the-art method for federated learning on non-IID image data. The "N=100" condition highlights the algorithm's scalability to many clients.