\n
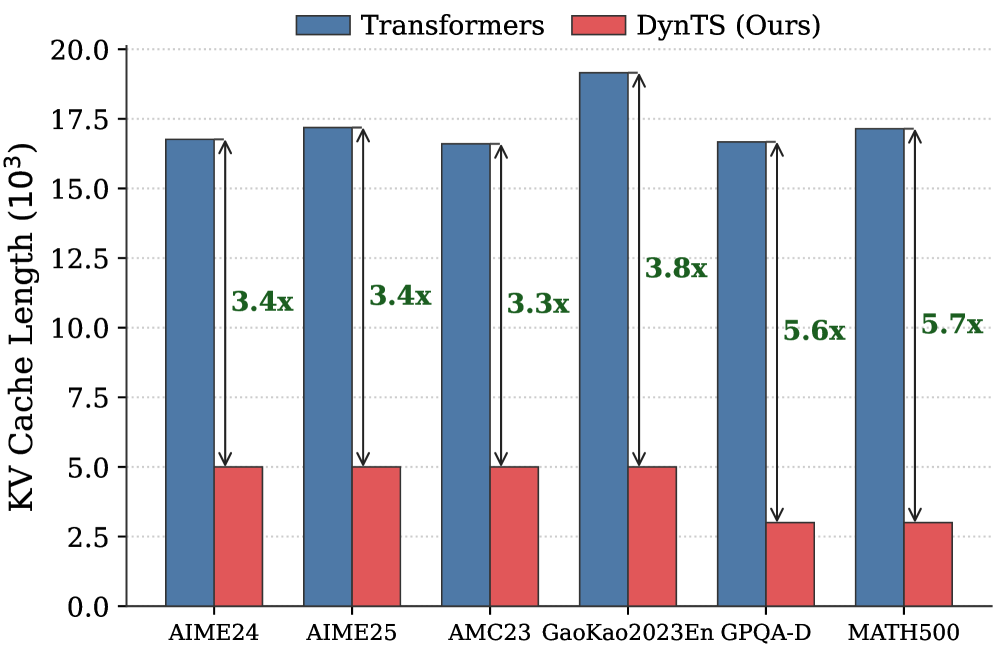
## Grouped Bar Chart: KV Cache Length Comparison Between Transformers and DynTS
### Overview
This image is a grouped bar chart comparing the Key-Value (KV) Cache Length (in thousands) of two models—"Transformers" and "DynTS (Ours)"—across six different benchmark datasets. The chart visually demonstrates the memory efficiency advantage of the DynTS model.
### Components/Axes
* **Chart Type:** Grouped vertical bar chart.
* **Y-Axis:**
* **Label:** "KV Cache Length (10³)" - indicating the values are in thousands.
* **Scale:** Linear scale from 0.0 to 20.0, with major tick marks every 2.5 units (0.0, 2.5, 5.0, 7.5, 10.0, 12.5, 15.0, 17.5, 20.0).
* **X-Axis:**
* **Categories (Datasets):** Six distinct datasets are listed from left to right: `AIME24`, `AIME25`, `AMC23`, `GaoKao2023En`, `GPQA-D`, `MATH500`.
* **Legend:**
* **Position:** Top center of the chart area.
* **Labels & Colors:**
* Blue square: `Transformers`
* Red square: `DynTS (Ours)`
* **Data Series & Annotations:**
* For each dataset, there is a pair of bars: a blue bar (Transformers) on the left and a red bar (DynTS) on the right.
* A double-headed vertical arrow spans the height difference between the top of the blue bar and the top of the red bar for each pair.
* A green text label is placed next to each arrow, indicating the multiplicative reduction factor (e.g., "3.4x").
### Detailed Analysis
The analysis proceeds dataset by dataset, from left to right. For each, the visual trend is that the blue bar (Transformers) is significantly taller than the red bar (DynTS).
1. **AIME24:**
* **Transformers (Blue):** Approximately 17.0 (10³).
* **DynTS (Red):** Approximately 5.0 (10³).
* **Multiplier Annotation:** "3.4x" (indicating the Transformer cache is ~3.4 times larger).
2. **AIME25:**
* **Transformers (Blue):** Approximately 17.2 (10³).
* **DynTS (Red):** Approximately 5.0 (10³).
* **Multiplier Annotation:** "3.4x".
3. **AMC23:**
* **Transformers (Blue):** Approximately 16.7 (10³).
* **DynTS (Red):** Approximately 5.0 (10³).
* **Multiplier Annotation:** "3.3x".
4. **GaoKao2023En:**
* **Transformers (Blue):** Approximately 19.2 (10³) - this is the highest value for Transformers.
* **DynTS (Red):** Approximately 5.0 (10³).
* **Multiplier Annotation:** "3.8x".
5. **GPQA-D:**
* **Transformers (Blue):** Approximately 16.7 (10³).
* **DynTS (Red):** Approximately 3.0 (10³) - this is the lowest value for DynTS.
* **Multiplier Annotation:** "5.6x".
6. **MATH500:**
* **Transformers (Blue):** Approximately 17.2 (10³).
* **DynTS (Red):** Approximately 3.0 (10³).
* **Multiplier Annotation:** "5.7x" - this is the largest reduction factor shown.
### Key Observations
* **Consistent Reduction:** The KV Cache Length for DynTS is consistently and substantially lower than that of the standard Transformer model across all six benchmarks.
* **Magnitude of Improvement:** The reduction factor ranges from 3.3x to 5.7x. The most significant improvements are seen on the `GPQA-D` and `MATH500` datasets.
* **Transformer Cache Length:** The cache length for Transformers is relatively stable across datasets, hovering between approximately 16.7 and 19.2 (10³), with `GaoKao2023En` being the peak.
* **DynTS Cache Length:** The cache length for DynTS shows two tiers: approximately 5.0 (10³) for the first four datasets and a lower tier of approximately 3.0 (10³) for `GPQA-D` and `MATH500`.
### Interpretation
This chart presents strong empirical evidence for the memory efficiency of the proposed "DynTS" model compared to a standard Transformer architecture. The KV cache is a critical component in autoregressive models (like LLMs) that stores past key and value states to avoid recomputation, and its size directly impacts memory consumption and cost during inference.
The data suggests that DynTS achieves a dramatic reduction in this memory overhead—by a factor of 3.3 to 5.7 times—without specifying performance parity on the tasks themselves. This implies DynTS likely employs a dynamic or more efficient mechanism for managing or compressing the KV cache. The variation in the reduction factor across datasets indicates that the efficiency gain may be task-dependent, with particularly large savings on complex reasoning benchmarks like `MATH500` and `GPQA-D`. The primary takeaway is that DynTS offers a significant practical advantage for deploying large models in memory-constrained environments.