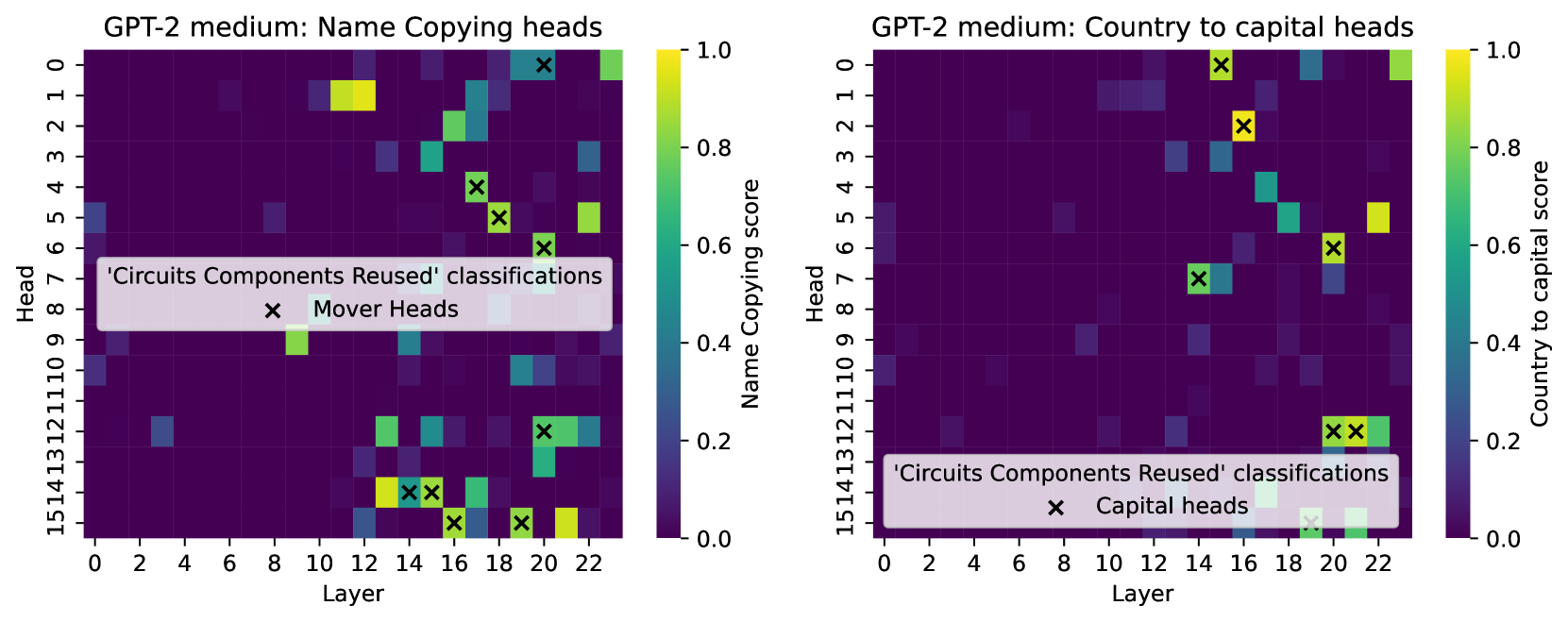
\n
## Heatmap Chart: GPT-2 Medium Attention Head Analysis
### Overview
The image displays two side-by-side heatmaps visualizing the performance scores of attention heads within the GPT-2 medium model on two distinct tasks: "Name Copying" (left) and "Country to Capital" (right). Each heatmap plots "Head" index (y-axis) against "Layer" index (x-axis), with cell color indicating a task-specific score. Overlaid on both heatmaps are 'x' markers indicating heads classified as part of reused circuit components for each task.
### Components/Axes
**Common Elements (Both Charts):**
* **Chart Type:** Heatmap.
* **Y-axis:** Labeled "Head". Ticks range from 0 to 15 in increments of 1.
* **X-axis:** Labeled "Layer". Ticks range from 0 to 22 in increments of 2 (0, 2, 4, ..., 22).
* **Color Scale:** A vertical color bar on the right of each chart maps color to a score from 0.0 (dark purple) to 1.0 (bright yellow). The gradient passes through blue and green.
* **Legend/Annotation:** A semi-transparent white box contains the text "'Circuits Components Reused' classifications" and a key showing a black 'x' symbol with a label.
**Left Chart Specifics:**
* **Title:** "GPT-2 medium: Name Copying heads"
* **Color Bar Label:** "Name Copying score"
* **Legend Label (for 'x'):** "Mover Heads"
* **Legend Position:** Lower-left quadrant, overlapping data cells in approximately layers 0-10, heads 6-9.
**Right Chart Specifics:**
* **Title:** "GPT-2 medium: Country to capital heads"
* **Color Bar Label:** "Country to capital score"
* **Legend Label (for 'x'):** "Capital heads"
* **Legend Position:** Lower-right quadrant, overlapping data cells in approximately layers 14-22, heads 12-15.
### Detailed Analysis
**Left Chart: Name Copying Heads**
* **Trend:** High scores (yellow/green) are concentrated in the later layers (approximately layers 12-22) across various heads. The earlier layers (0-10) show predominantly low scores (dark purple/blue), with a few isolated medium-score cells.
* **High-Score Cells (Approximate):**
* Layer 14, Head 1: Score ~1.0 (bright yellow).
* Layer 16, Head 0: Score ~0.9 (yellow-green).
* Layer 22, Head 5: Score ~0.8 (green).
* Layer 14, Head 14: Score ~0.9 (yellow).
* Layer 22, Head 15: Score ~0.9 (yellow).
* **'x' Marker (Mover Heads) Positions:** The 'x' markers are placed on specific cells, indicating heads classified as "Mover Heads." Their approximate (Layer, Head) coordinates are:
* (14, 4), (15, 5), (16, 6), (18, 0), (20, 12), (14, 14), (15, 14), (16, 15), (18, 15), (20, 15).
* **Verification:** These markers generally, but not exclusively, overlay cells with medium to high scores (green/yellow). For example, the marker at (14, 14) is on a high-score yellow cell, while the marker at (16, 6) is on a medium-score green cell.
**Right Chart: Country to Capital Heads**
* **Trend:** High scores are more sparsely distributed compared to the left chart. Notable high-score clusters appear in layers 14-16 and around layer 22.
* **High-Score Cells (Approximate):**
* Layer 14, Head 0: Score ~1.0 (bright yellow).
* Layer 16, Head 2: Score ~0.9 (yellow).
* Layer 22, Head 5: Score ~0.8 (green).
* Layer 20, Head 12: Score ~0.7 (green).
* Layer 22, Head 12: Score ~0.7 (green).
* **'x' Marker (Capital heads) Positions:** The 'x' markers indicate heads classified as "Capital heads." Their approximate (Layer, Head) coordinates are:
* (14, 0), (15, 2), (16, 6), (14, 7), (20, 12), (21, 12), (20, 15), (21, 15).
* **Verification:** These markers show a strong correlation with high-score cells. The markers at (14, 0) and (15, 2) are directly on bright yellow cells. The cluster at layers 20-21, heads 12 and 15, also aligns with green cells.
### Key Observations
1. **Task-Specific Specialization:** The heatmaps reveal that different sets of attention heads are activated for different tasks. The pattern of high-scoring cells is distinct between "Name Copying" and "Country to Capital."
2. **Layer Preference:** Both tasks show a preference for heads in the middle to later layers (roughly 12-22) for high performance, with very few high-scoring heads in the first 10 layers.
3. **Circuit Reuse:** The 'x' markers highlight heads identified as part of reusable circuit components. In both charts, these marked heads often (but not always) correspond to cells with elevated scores, suggesting a link between a head's functional classification and its task performance.
4. **Marker Density:** The "Name Copying" task has more 'x' markers (10) spread across layers 14-20, while the "Country to Capital" task has 8 markers, with a notable cluster in the final layers (20-21).
### Interpretation
This visualization provides evidence for the **modular and distributed nature of knowledge** within a transformer language model like GPT-2. The data suggests:
* **Functional Localization:** Specific capabilities (like copying names or recalling capitals) are not handled by a single, monolithic component but are distributed across multiple attention heads, primarily in the model's deeper layers where more abstract processing is believed to occur.
* **Circuit Reusability:** The overlay of "Circuits Components Reused" classifications implies that the model reuses certain architectural components (attention heads) for multiple, potentially related, tasks. A head classified as a "Mover Head" for name copying might also play a role in other information movement tasks, while a "Capital head" is likely specialized for entity-relation lookup.
* **Investigative Insight:** The discrepancy where some high-score cells lack an 'x' marker (e.g., Layer 22, Head 5 in both charts) is notable. This could indicate heads that are highly effective for a specific task but are not part of the core, reused circuit identified by the "Circuits Components Reused" analysis framework. Conversely, a marked head with a lower score might be a necessary but insufficient component of a larger circuit.
* **Practical Implication:** For researchers in mechanistic interpretability, this map serves as a guide. It pinpoints which heads (e.g., Layer 14 Head 1 for names, Layer 14 Head 0 for capitals) are most critical to investigate to understand how these specific facts or operations are encoded and retrieved within the model's network.