## Model Architecture Timeline
### Overview
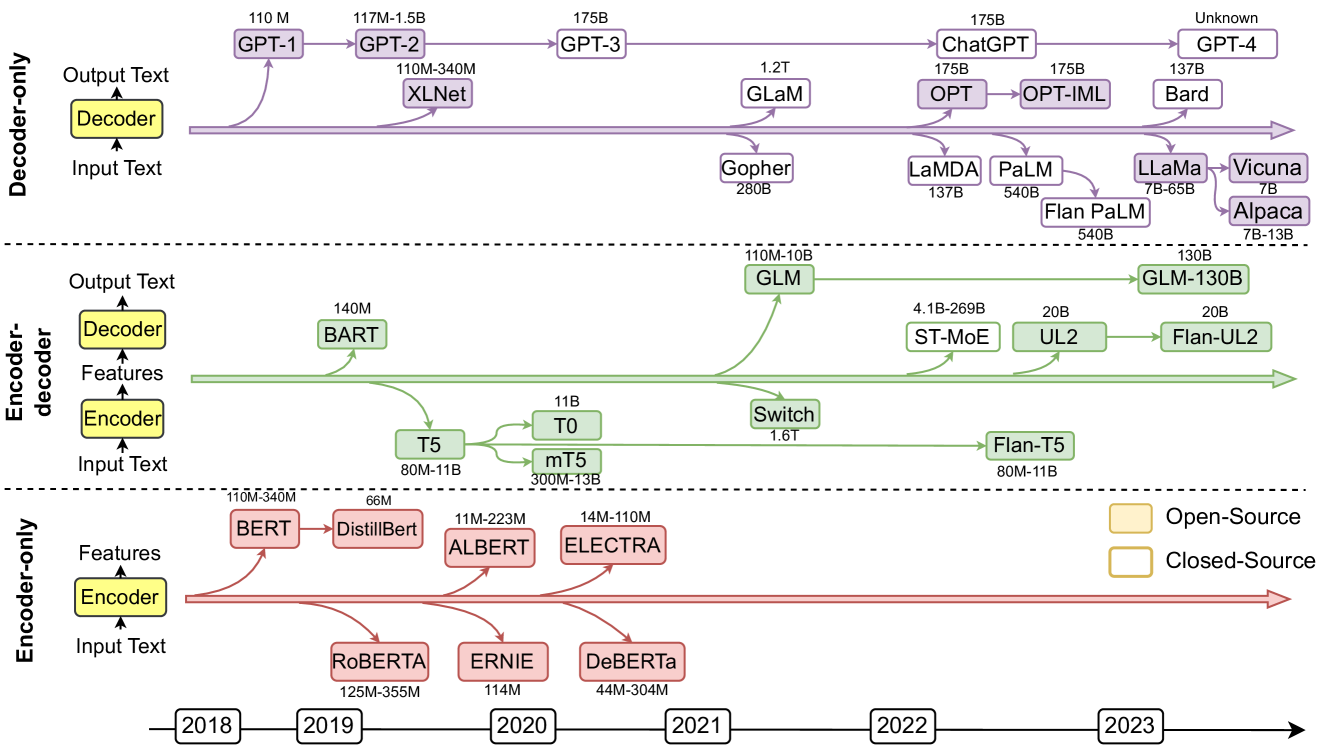
The image presents a timeline of language model architectures, categorized by their encoder-decoder structure (Decoder-only, Encoder-decoder, Encoder-only). It shows the evolution of various models over time (2018-2023), indicating their names and parameter sizes. The models are color-coded to distinguish between open-source (yellow) and closed-source (red/purple/green).
### Components/Axes
* **Y-Axis Categories:**
* Decoder-only
* Encoder-decoder
* Encoder-only
* **X-Axis:** Timeline from 2018 to 2023.
* **Legend:** Located at the bottom-right of the image.
* Open-Source (Yellow)
* Closed-Source (Red/Purple/Green)
* **Architecture Blocks:** Each architecture type (Decoder, Encoder) is represented by a yellow block with an upward arrow indicating "Output Text" or "Features" and a downward arrow indicating "Input Text".
### Detailed Analysis or ### Content Details
**1. Decoder-only Models (Purple):**
* **2018:** GPT-1 (110M parameters)
* **2019:** GPT-2 (117M-1.5B parameters), XLNet (110M-340M parameters)
* **2020:** GPT-3 (175B parameters)
* **2022:** GLaM (1.2T parameters), OPT (175B parameters)
* **2023:** ChatGPT (175B parameters), OPT-IML (175B parameters), Bard (137B parameters), GPT-4 (Unknown parameters), Gopher (280B parameters), LaMDA (137B parameters), PaLM (540B parameters), Flan PaLM (540B parameters), LLaMa (7B-65B parameters), Vicuna (7B parameters), Alpaca (7B-13B parameters)
**Trend:** The Decoder-only models show a clear trend of increasing parameter size over time, with a significant jump from GPT-1 to GPT-3.
**2. Encoder-decoder Models (Green):**
* **2019:** BART (140M parameters), T5 (80M-11B parameters)
* **2020:** T0 (11B parameters), mT5 (300M-13B parameters)
* **2021:** GLM (110M-10B parameters), Switch (1.6T parameters)
* **2022:** ST-MoE (4.1B-269B parameters), UL2 (20B parameters), Flan-T5 (80M-11B parameters)
* **2023:** GLM-130B (130B parameters), Flan-UL2 (20B parameters)
**Trend:** The Encoder-decoder models also show an increase in parameter size, but with more variation compared to the Decoder-only models.
**3. Encoder-only Models (Red):**
* **2018:** BERT (110M-340M parameters)
* **2019:** DistillBert (66M parameters), RoBERTa (125M-355M parameters)
* **2020:** ALBERT (11M-223M parameters), ERNIE (114M parameters), DeBERTa (44M-304M parameters)
* **2021:** No models listed.
* **2022:** No models listed.
* **2023:** No models listed.
**Trend:** The Encoder-only models appear to have been most prominent in the earlier years (2018-2020), with no new models listed after 2020.
### Key Observations
* **Parameter Size Growth:** There is a general trend of increasing model parameter size across all architectures over time.
* **Architecture Shift:** The timeline suggests a shift in focus from Encoder-only models to Decoder-only and Encoder-decoder models in later years.
* **Open-Source vs. Closed-Source:** Both open-source and closed-source models are present in each category, but the specific ratio is not quantifiable from the image alone.
* **GPT-4:** The parameter size for GPT-4 is listed as "Unknown," indicating that this information was not publicly available at the time the diagram was created.
### Interpretation
The diagram illustrates the rapid evolution of language models, highlighting the increasing complexity and size of these models over a relatively short period. The shift in architectural focus suggests that researchers and developers are exploring different approaches to improve model performance. The presence of both open-source and closed-source models indicates a diverse landscape of development and innovation in the field of natural language processing. The trend of increasing parameter size suggests that larger models are generally considered to be more capable, although this may come at the cost of increased computational resources and training time.