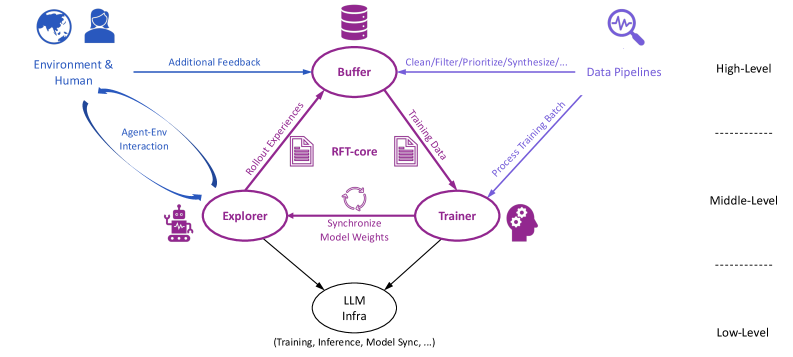
## Diagram: RFT-core System Architecture
### Overview
The image is a system architecture diagram illustrating the flow of data and interactions within an RFT-core system. It depicts the relationships between the Environment & Human, Buffer, Explorer, Trainer, and LLM Infra components, highlighting data pipelines and feedback loops. The diagram is structured into three levels: High-Level, Middle-Level, and Low-Level.
### Components/Axes
* **Levels:**
* High-Level
* Middle-Level
* Low-Level
* **Nodes:**
* Environment & Human (top-left)
* Buffer (top-center)
* Explorer (bottom-left)
* Trainer (bottom-right)
* LLM Infra (bottom-center)
* **Data Flow Arrows:**
* Additional Feedback (Environment & Human -> Buffer, blue)
* Agent-Env Interaction (Environment & Human <-> Explorer, blue)
* Rollout Experiences (Explorer -> Buffer, purple)
* Training Data (Buffer -> Trainer, purple)
* Synchronize Model Weights (Explorer <-> Trainer, purple)
* Process Training Batch (Trainer -> Buffer, blue)
* LLM Infra (Explorer -> LLM Infra, purple)
* LLM Infra (Trainer -> LLM Infra, purple)
* **Other Labels:**
* Data Pipelines (near Buffer, right, blue)
* RFT-core (center, between Buffer, Explorer, and Trainer)
* Clean/Filter/Prioritize/Synthesize/... (Buffer -> Data Pipelines, blue)
* (Training, Inference, Model Sync, ...) (below LLM Infra)
### Detailed Analysis or ### Content Details
* **Environment & Human:** Located at the top-left, this represents the external environment and human interaction. A blue arrow labeled "Additional Feedback" points from this component to the "Buffer." A curved blue arrow labeled "Agent-Env Interaction" indicates a two-way interaction between "Environment & Human" and "Explorer."
* **Buffer:** Positioned at the top-center, the "Buffer" receives "Additional Feedback" from "Environment & Human" and "Rollout Experiences" from "Explorer." It sends "Training Data" to the "Trainer" and "Clean/Filter/Prioritize/Synthesize/..." to "Data Pipelines." The "Trainer" sends "Process Training Batch" to the "Buffer."
* **Explorer:** Located at the bottom-left, the "Explorer" interacts with the "Environment & Human" via "Agent-Env Interaction." It sends "Rollout Experiences" to the "Buffer" and connects to the "Trainer" via "Synchronize Model Weights." The "Explorer" also connects to the "LLM Infra."
* **Trainer:** Situated at the bottom-right, the "Trainer" receives "Training Data" from the "Buffer" and connects to the "Explorer" via "Synchronize Model Weights." It sends "Process Training Batch" to the "Buffer" and connects to the "LLM Infra."
* **LLM Infra:** Positioned at the bottom-center, the "LLM Infra" receives input from both the "Explorer" and the "Trainer." The text below it reads "(Training, Inference, Model Sync, ...)," indicating its functions.
* **RFT-core:** Located in the center of the diagram, between the Buffer, Explorer, and Trainer.
* **Data Pipelines:** Located to the right of the Buffer, at the High-Level.
### Key Observations
* The diagram illustrates a cyclical flow of data and interactions between the core components: "Buffer," "Explorer," and "Trainer."
* The "Environment & Human" provides external input and feedback to the system.
* The "LLM Infra" serves as a central component for training, inference, and model synchronization.
* The diagram is divided into three levels, suggesting a hierarchical structure of the system.
### Interpretation
The diagram represents a Reinforcement Learning from Feedback (RFT-core) system architecture. The "Environment & Human" provides the environment and feedback, which is used by the "Explorer" to generate experiences. These experiences are stored in the "Buffer," which then provides training data to the "Trainer." The "Trainer" updates the model weights, which are synchronized with the "Explorer." The "LLM Infra" likely represents the infrastructure used for training, inference, and model synchronization of a Large Language Model (LLM). The cyclical nature of the diagram highlights the iterative process of reinforcement learning. The "Data Pipelines" suggest a process of cleaning, filtering, prioritizing, and synthesizing data before it is used for training. The three levels (High, Middle, Low) likely represent different levels of abstraction or detail in the system architecture.