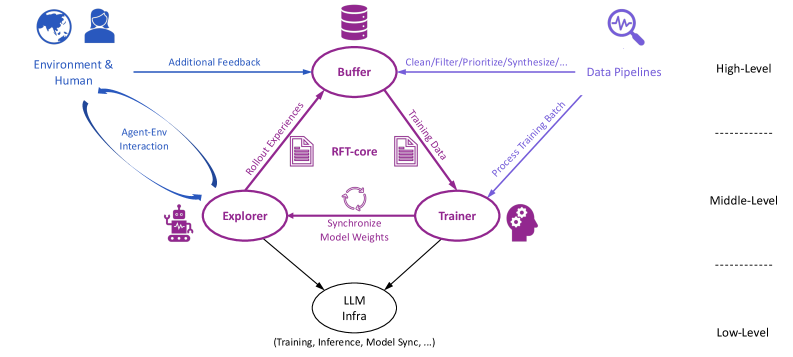
## System Architecture Diagram: Reinforcement Learning Training Pipeline
### Overview
This image is a technical system architecture diagram illustrating a multi-level reinforcement learning or model training pipeline. It depicts the flow of data, feedback, and model updates between distinct functional components, organized into three hierarchical levels: High-Level, Middle-Level, and Low-Level. The diagram uses a combination of labeled components (represented by icons and text), directional arrows with descriptive labels, and a clear spatial layout to explain the system's operation.
### Components/Axes
The diagram is structured vertically into three distinct tiers, separated by horizontal dashed lines.
**High-Level (Top Section):**
* **Components:**
* **Environment & Human:** Located top-left, represented by a globe and a person icon.
* **Buffer:** Located top-center, represented by a database cylinder icon.
* **Data Pipelines:** Located top-right, represented by a magnifying glass over a waveform icon.
* **Flow/Connections:**
* An arrow labeled **"Additional Feedback"** flows from *Environment & Human* to *Buffer*.
* An arrow labeled **"Clean/Filter/Prioritize/Synthesize/..."** flows from *Data Pipelines* to *Buffer*.
* A bidirectional arrow labeled **"Agent-Env Interaction"** connects *Environment & Human* to the *Explorer* component in the Middle-Level.
**Middle-Level (Center Section):**
* **Components:**
* **Explorer:** Located center-left, represented by a robot icon.
* **RFT-core:** Located at the very center, represented by two document icons with a circular arrow between them.
* **Trainer:** Located center-right, represented by a human head with gears icon.
* **Flow/Connections:**
* An arrow labeled **"Robust Experiences"** flows from *Explorer* to *Buffer* (High-Level).
* An arrow labeled **"Trained Data"** flows from *Buffer* (High-Level) to *Trainer*.
* An arrow labeled **"Process Training Batch"** flows from *Data Pipelines* (High-Level) to *Trainer*.
* A bidirectional arrow labeled **"Synchronize Model Weights"** connects *Explorer* and *Trainer*.
* Arrows flow from both *Explorer* and *Trainer* down to the *LLM Infra* component in the Low-Level.
**Low-Level (Bottom Section):**
* **Components:**
* **LLM Infra:** Located bottom-center, represented by a simple oval.
* **Text/Notes:**
* Below the *LLM Infra* oval, the text reads: **"(Training, Inference, Model Sync, ...)"**.
### Detailed Analysis
The diagram explicitly maps the data and control flow for a training system:
1. **Data Ingestion & Curation (High-Level):** Raw data or signals enter via *Data Pipelines* and are processed (cleaned, filtered, etc.) before being sent to the central *Buffer*. Concurrently, the *Environment & Human* provide *Additional Feedback* directly to the *Buffer*.
2. **Experience Generation & Training (Middle-Level):**
* The *Explorer* component interacts with the *Environment & Human* (via the "Agent-Env Interaction" loop) to generate experiences.
* These experiences are sent as **"Robust Experiences"** to the *Buffer*.
* The *Buffer* acts as a central repository, sending curated **"Trained Data"** to the *Trainer*.
* The *Trainer* also receives a direct feed of processed data via the **"Process Training Batch"** arrow from *Data Pipelines*.
* The *Explorer* and *Trainer* maintain synchronized model weights, indicated by the bidirectional arrow.
* The central **RFT-core** (likely standing for Reinforcement Fine-Tuning core) is positioned between the *Explorer* and *Trainer*, suggesting it is the core algorithm or logic coordinating their interaction.
3. **Infrastructure Layer (Low-Level):** Both the *Explorer* and *Trainer* components depend on the underlying **LLM Infra**, which handles fundamental operations like training runs, inference serving, and model synchronization.
### Key Observations
* **Central Buffer:** The *Buffer* is a critical hub, receiving inputs from three sources (*Data Pipelines*, *Environment & Human*, *Explorer*) and providing output to the *Trainer*.
* **Dual Data Paths to Trainer:** The *Trainer* receives data from two distinct sources: curated data from the *Buffer* and a direct processed batch from *Data Pipelines*.
* **Synchronization Emphasis:** The explicit "Synchronize Model Weights" link between *Explorer* and *Trainer* highlights the importance of keeping these two active components aligned.
* **Hierarchical Abstraction:** The three-level structure clearly separates high-level data/feedback sources, middle-level processing agents, and low-level infrastructure.
### Interpretation
This diagram outlines a sophisticated, closed-loop system for training a large language model (LLM) using reinforcement learning or interactive fine-tuning. The **Explorer** likely acts as an agent that explores an environment (which could be a simulation, a user interface, or a dataset) to generate novel experiences or data. These experiences are stored and refined in the **Buffer**. The **Trainer** uses this buffered data, along with directly processed batches, to update the model. The constant synchronization ensures the exploring agent and the training module are working with the same model version.
The system is designed for continuous improvement: the model's interactions generate new training data, which is used to improve the model, which in turn leads to better interactions. The inclusion of **Human** and **Environment** feedback at the high level indicates this is likely a human-in-the-loop or interactive learning system, where external feedback directly influences the training data pool. The **RFT-core** is the central nervous system, orchestrating the exchange of experiences and training data between the explorer and trainer. The entire process is built upon a shared **LLM Infra** foundation.