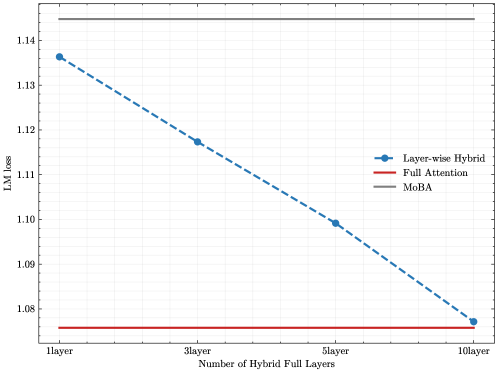
## Line Chart: LM Loss vs. Number of Hybrid Full Layers
### Overview
The chart compares the language model (LM) loss performance of three architectures—Layer-wise Hybrid, Full Attention, and MoBA—as the number of hybrid full layers increases from 1 to 10. The y-axis represents LM loss (lower values indicate better performance), while the x-axis represents the number of hybrid full layers. The Layer-wise Hybrid architecture shows a clear downward trend, while Full Attention and MoBA remain constant.
---
### Components/Axes
- **X-axis (Horizontal)**:
- Title: "Number of Hybrid Full Layers"
- Labels: "1layer", "3layer", "5layer", "10layer"
- Scale: Discrete increments (1 → 3 → 5 → 10 layers).
- **Y-axis (Vertical)**:
- Title: "LM loss"
- Range: 1.08 to 1.14 (with gridlines at 0.01 intervals).
- **Legend**:
- Position: Right side of the chart.
- Entries:
- **Layer-wise Hybrid**: Dashed blue line with circular markers.
- **Full Attention**: Solid red line.
- **MoBA**: Solid gray line.
---
### Detailed Analysis
1. **Layer-wise Hybrid (Dashed Blue Line)**:
- **Trend**: Steadily decreases from ~1.135 at 1layer to ~1.075 at 10layer.
- **Key Data Points**:
- 1layer: ~1.135
- 3layer: ~1.115
- 5layer: ~1.10
- 10layer: ~1.075
2. **Full Attention (Solid Red Line)**:
- **Trend**: Flat line at ~1.075 across all layers.
3. **MoBA (Solid Gray Line)**:
- **Trend**: Flat line at ~1.14 across all layers.
---
### Key Observations
- **Layer-wise Hybrid** demonstrates a consistent improvement in LM loss as the number of hybrid layers increases.
- **Full Attention** and **MoBA** show no improvement, maintaining constant loss values regardless of layer count.
- **MoBA** consistently exhibits the highest LM loss (~1.14), suggesting suboptimal performance compared to the other architectures.
---
### Interpretation
The chart highlights the effectiveness of the **Layer-wise Hybrid** architecture in reducing LM loss with increased hybrid layers, outperforming both **Full Attention** and **MoBA**. The flat performance of **Full Attention** and **MoBA** implies that their architectures do not benefit from additional hybrid layers in terms of LM loss reduction. **MoBA**'s persistently high loss suggests potential inefficiencies in its design or training process. This analysis underscores the importance of architectural choices in balancing model complexity and performance gains.