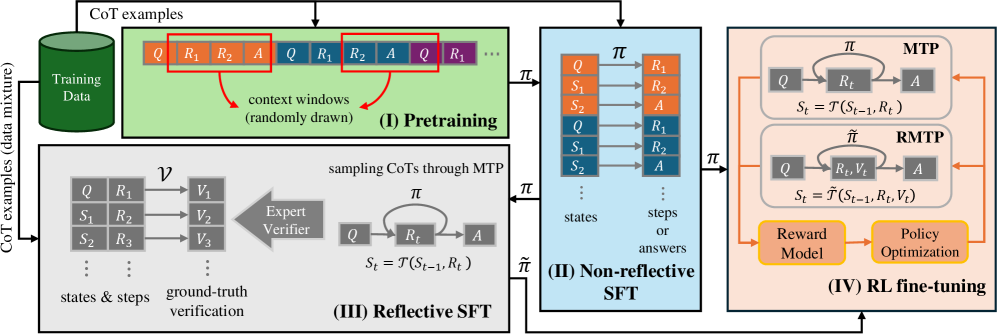
## Diagram: Training Pipeline for Conversational Agents
### Overview
The image depicts a four-stage training pipeline for conversational agents, starting with pretraining on a mixture of CoT (Chain-of-Thought) examples and culminating in Reinforcement Learning fine-tuning (RL fine-tuning). The pipeline leverages techniques like MTP (Model-based Trajectory Planning), RMTMP (Reward-Model-based Trajectory Planning), and an Expert Verifier. The diagram illustrates the flow of data and the transformations applied at each stage.
### Components/Axes
The diagram is divided into four main sections, labeled (I) through (IV), representing the stages of the training process. Each section contains boxes and arrows illustrating data flow and processing. Key elements include:
* **CoT examples (data mixture):** The initial training data, consisting of question-reasoning-answer sequences.
* **Q:** Represents a question.
* **R1, R2, R3...:** Represents reasoning steps.
* **A:** Represents the answer.
* **S1, S2, S3...:** Represents states.
* **π:** Represents a policy.
* **ν:** Represents ground-truth verification.
* **V1, V2, V3...:** Represents verification scores.
* **MTP:** Model-based Trajectory Planning.
* **RMTMP:** Reward-Model-based Trajectory Planning.
* **Reward Model:** A component used in RL fine-tuning.
* **Policy Optimization:** A component used in RL fine-tuning.
### Detailed Analysis or Content Details
**(I) Pretraining:**
* The process begins with a "Training Data" block containing CoT examples. These examples are represented as sequences of Q, R1, R2, A, etc.
* "Context windows (randomly drawn)" are extracted from the CoT examples. These windows are fed into the next stage.
**(II) Non-reflective SFT:**
* The output of the Pretraining stage is fed into the "Non-reflective SFT" (Supervised Fine-Tuning) stage.
* The input is a sequence of states and steps/answers.
* The policy π is used to generate an action A based on the current state S.
* The state transitions to S<sub>t</sub> = τ(S<sub>t-1</sub>, R<sub>t</sub>).
**(III) Reflective SFT:**
* This stage introduces an "Expert Verifier" that evaluates the generated reasoning steps.
* The Expert Verifier provides verification scores (V1, V2, V3...) for the ground-truth verification.
* The policy π is used to generate an action A based on the current state S.
* The state transitions to S<sub>t</sub> = τ(S<sub>t-1</sub>, R<sub>t</sub>).
* Sampling CoTs is done through MTP.
**(IV) RL fine-tuning:**
* This stage utilizes both MTP and RMTMP.
* MTP takes the policy π and generates actions A based on states Q and reasoning steps R1, R2.
* RMTMP incorporates a "Reward Model" to evaluate the generated responses.
* The state transitions to S<sub>t</sub> = τ(S<sub>t-1</sub>, R<sub>t</sub>, V<sub>t</sub>).
* "Policy Optimization" is performed based on the rewards received from the Reward Model.
* An arrow indicates feedback from the RL fine-tuning stage back to the Non-reflective SFT stage.
### Key Observations
* The pipeline progressively refines the conversational agent's capabilities.
* The introduction of the Expert Verifier in stage (III) adds a layer of quality control.
* The use of MTP and RMTMP in stage (IV) enables reinforcement learning based on both model-based and reward-based feedback.
* The feedback loop from RL fine-tuning to Non-reflective SFT suggests iterative refinement of the model.
### Interpretation
The diagram illustrates a sophisticated training pipeline for building high-quality conversational agents. The pipeline moves from initial pretraining on a large dataset of CoT examples to supervised fine-tuning, then to a reflective SFT stage that incorporates expert verification, and finally to reinforcement learning fine-tuning. The use of MTP and RMTMP suggests a focus on planning and reward maximization. The feedback loop indicates a commitment to continuous improvement. The diagram highlights the importance of both supervised learning and reinforcement learning in achieving optimal performance. The inclusion of an Expert Verifier suggests a desire to ensure the generated reasoning steps are accurate and reliable. The overall architecture is designed to create a conversational agent that can not only generate coherent responses but also provide accurate and well-reasoned answers. The diagram suggests a focus on building agents that can "think" through problems and explain their reasoning, rather than simply providing answers.