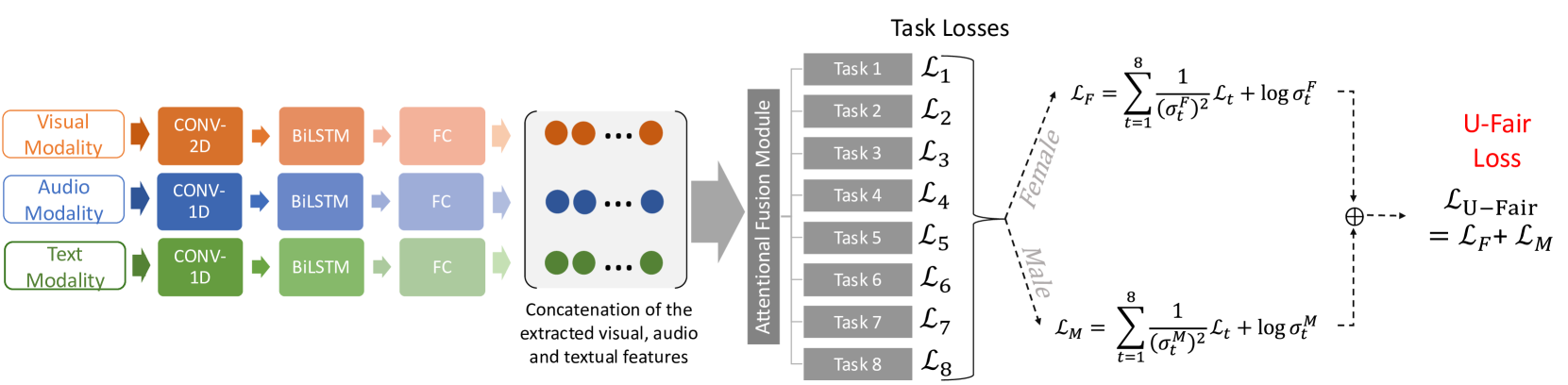
## Diagram: U-Fair Loss Calculation
### Overview
The image is a diagram illustrating the process of calculating the U-Fair Loss. It shows the flow of data from different modalities (visual, audio, text) through convolutional and recurrent layers, their fusion, and the subsequent calculation of task losses, ultimately leading to the U-Fair Loss.
### Components/Axes
* **Input Modalities (Left)**:
* Visual Modality (orange)
* Audio Modality (blue)
* Text Modality (green)
* **Processing Layers (Left)**:
* CONV-2D (orange, for visual)
* CONV-1D (blue, for audio; green, for text)
* BiLSTM (orange, blue, green)
* FC (Fully Connected Layer) (light orange, light blue, light green)
* **Feature Concatenation (Center-Left)**:
* Concatenation of the extracted visual, audio and textual features (represented by colored circles: orange, blue, green)
* **Attentional Fusion Module (Center)**:
* A gray arrow pointing right, labeled "Attentional Fusion Module"
* **Task Losses (Center-Right)**:
* Task 1: L1
* Task 2: L2
* Task 3: L3
* Task 4: L4
* Task 5: L5
* Task 6: L6
* Task 7: L7
* Task 8: L8
* **Loss Calculation (Right)**:
* L\_F (Female Loss)
* L\_M (Male Loss)
* L\_U-Fair (U-Fair Loss)
### Detailed Analysis or ### Content Details
1. **Modality Processing**:
* Visual Modality (orange) -> CONV-2D -> BiLSTM -> FC
* Audio Modality (blue) -> CONV-1D -> BiLSTM -> FC
* Text Modality (green) -> CONV-1D -> BiLSTM -> FC
2. **Feature Concatenation**:
* The outputs of the FC layers are concatenated into a single feature vector.
3. **Attentional Fusion**:
* The concatenated features are passed through an Attentional Fusion Module.
4. **Task Losses**:
* The output of the Attentional Fusion Module is used to calculate task-specific losses (L1 to L8).
5. **Loss Calculation**:
* The task losses are used to calculate the Female Loss (L\_F) and Male Loss (L\_M).
* The U-Fair Loss (L\_U-Fair) is the sum of the Female Loss and Male Loss.
**Equations**:
* **Female Loss (L\_F)**:
* L\_F = ∑ (from t=1 to 8) \[ 1 / ((σ\_t^F)^2) * L\_t + log σ\_t^F ]
* **Male Loss (L\_M)**:
* L\_M = ∑ (from t=1 to 8) \[ 1 / ((σ\_t^M)^2) * L\_t + log σ\_t^M ]
* **U-Fair Loss (L\_U-Fair)**:
* L\_U-Fair = L\_F + L\_M
### Key Observations
* The diagram illustrates a multi-modal learning approach, combining visual, audio, and text data.
* The use of convolutional and recurrent layers suggests that the model is designed to capture both spatial and temporal dependencies in the input data.
* The Attentional Fusion Module likely aims to weigh the contributions of different modalities based on their relevance to the task.
* The U-Fair Loss is designed to balance the performance of the model across different demographic groups (male and female).
### Interpretation
The diagram presents a system for multi-modal learning with a focus on fairness. The model processes visual, audio, and text data separately before fusing them using an attention mechanism. The U-Fair Loss function is designed to mitigate bias by explicitly considering the performance of the model on male and female demographics. This approach aims to improve the overall fairness and robustness of the model. The equations for L\_F and L\_M suggest that the model is trying to minimize the task losses (L\_t) while also regularizing the variance (σ\_t) to ensure fair performance across groups.