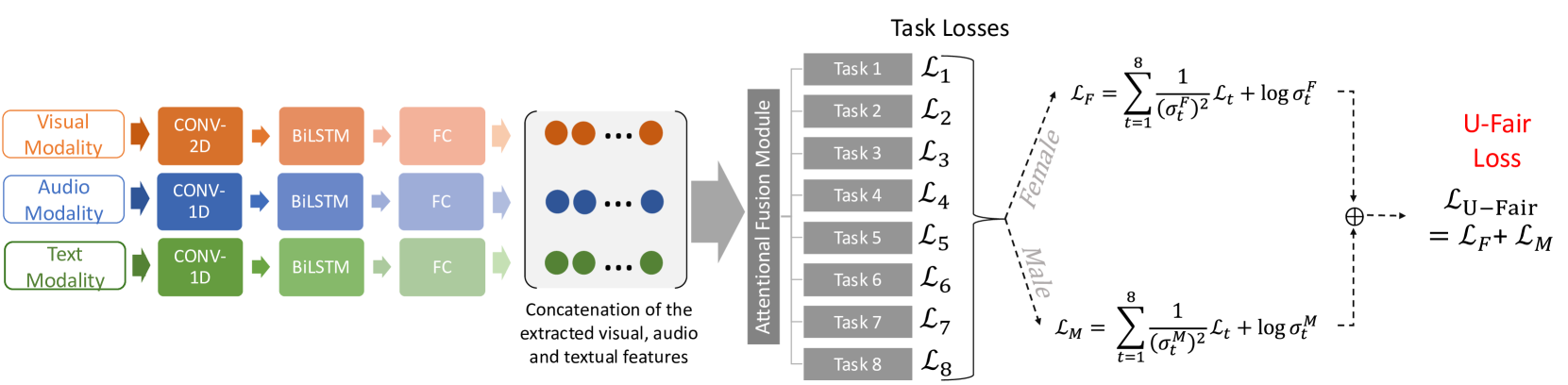
## [Diagram Type]: Multimodal Learning Architecture with Fairness-Aware Loss
### Overview
The image is a technical flowchart illustrating the architecture of a multimodal machine learning system designed for multiple tasks, incorporating a fairness-aware loss mechanism. The diagram shows the flow of data from three input modalities (Visual, Audio, Text) through separate processing pipelines, feature fusion, task-specific loss computation, and a final fairness loss calculation that accounts for gender (Female/Male).
### Components/Axes
The diagram is organized into four main regions from left to right:
1. **Input Modalities (Leftmost Region):**
* **Visual Modality** (Orange box, top-left)
* **Audio Modality** (Blue box, middle-left)
* **Text Modality** (Green box, bottom-left)
2. **Modality-Specific Processing Pipelines (Center-Left Region):**
Each modality feeds into a parallel processing chain:
* **Visual Pipeline:** `CONV-2D` -> `BiLSTM` -> `FC` (Fully Connected layer)
* **Audio Pipeline:** `CONV-1D` -> `BiLSTM` -> `FC`
* **Text Pipeline:** `CONV-1D` -> `BiLSTM` -> `FC`
* Arrows indicate the data flow direction between these components.
3. **Feature Fusion and Task Processing (Center Region):**
* **Concatenation Block:** A large rounded rectangle labeled "Concatenation of the extracted visual, audio and textual features". It contains three rows of colored dots (orange, blue, green) representing the fused feature vectors.
* **Attentional Fusion Module:** A vertical gray bar that receives the concatenated features.
* **Task Losses:** A column of eight gray boxes labeled `Task 1` through `Task 8`. Each is associated with a loss term: `L₁`, `L₂`, `L₃`, `L₄`, `L₅`, `L₆`, `L₇`, `L₈`.
4. **Fairness Loss Computation (Rightmost Region):**
* The task losses are split into two branches via dashed arrows:
* **Female Branch:** Labeled "Female" along the dashed arrow.
* **Male Branch:** Labeled "Male" along the dashed arrow.
* **Mathematical Formulas:**
* For the Female branch: `L_F = Σ_{t=1}^{8} (1/(σ_t^F)²) * L_t + log σ_t^F`
* For the Male branch: `L_M = Σ_{t=1}^{8} (1/(σ_t^M)²) * L_t + log σ_t^M`
* **Final Loss:** The two branches converge at a summation symbol (⊕). The final output is labeled in red text: **"U-Fair Loss"** with the equation: `L_U-Fair = L_F + L_M`.
### Detailed Analysis
* **Data Flow:** The process is sequential and parallel. Data from three modalities is processed independently, then fused. The fused representation is used to compute losses for eight distinct tasks. These task losses are then re-weighted and aggregated separately for female and male subgroups to compute a fairness-aware total loss.
* **Mathematical Notation:** The formulas use standard symbols:
* `Σ`: Summation from t=1 to 8 (for all tasks).
* `L_t`: The loss for task `t`.
* `σ_t^F`, `σ_t^M`: Likely represent learnable parameters (e.g., standard deviations or uncertainty weights) for each task `t`, specific to the Female (`F`) and Male (`M`) groups, respectively.
* The term `(1/(σ)²)` acts as an inverse variance weight, and `log σ` is a regularization term.
* **Spatial Grounding:** The legend (modality labels) is positioned at the far left. The core processing flows left-to-right. The fairness computation is isolated on the far right, with the gender-specific branches clearly diverging from the central task loss column.
### Key Observations
1. **Multimodal Architecture:** The system is explicitly designed to handle three distinct data types (visual, audio, text), using modality-appropriate initial layers (2D convolutions for visual, 1D for audio/text).
2. **Shared Processing Pattern:** After the initial convolution, all modalities pass through identical `BiLSTM` and `FC` layers, suggesting a common feature extraction strategy.
3. **Multi-Task Learning:** The model is trained on eight simultaneous tasks (`Task 1` to `Task 8`), as evidenced by the eight distinct loss terms (`L₁` to `L₈`).
4. **Fairness-Aware Objective:** The most distinctive feature is the **U-Fair Loss**. The model does not simply sum all task losses. Instead, it computes a separate, weighted sum of losses for female and male groups before combining them. This structure is designed to mitigate bias by explicitly accounting for performance disparities across gender groups.
5. **Attentional Fusion:** The "Attentional Fusion Module" suggests that the model dynamically weights the importance of features from different modalities when combining them, rather than using simple concatenation alone.
### Interpretation
This diagram represents a sophisticated neural network architecture for **fair multi-task multimodal learning**. The core innovation lies in the loss function (`L_U-Fair`).
* **What it demonstrates:** The system aims to perform well on eight different tasks while being fair across gender groups. The separate `L_F` and `L_M` calculations allow the model to monitor and control performance disparities. The weighting by `1/(σ)²` suggests tasks or groups with higher uncertainty (larger `σ`) contribute less to the final loss, potentially making the model more robust.
* **Relationships:** The modalities are complementary inputs. The tasks are the primary learning objectives. The fairness mechanism is a constraint or regularizer applied on top of the multi-task learning framework.
* **Notable Implications:** The "U-Fair" likely stands for "Uncertainty-aware Fair" or "Universal Fair." The architecture implies that fairness is not an afterthought but is baked into the core optimization objective. This is a technical approach to creating AI systems that are not only accurate but also equitable, which is critical for real-world applications involving human data (e.g., emotion recognition, speech analysis, or content moderation where gender bias is a known issue). The diagram provides a blueprint for implementing such a system.