TECHNICAL ASSET FINGERPRINT
e70dbff6dd369970884bed97
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
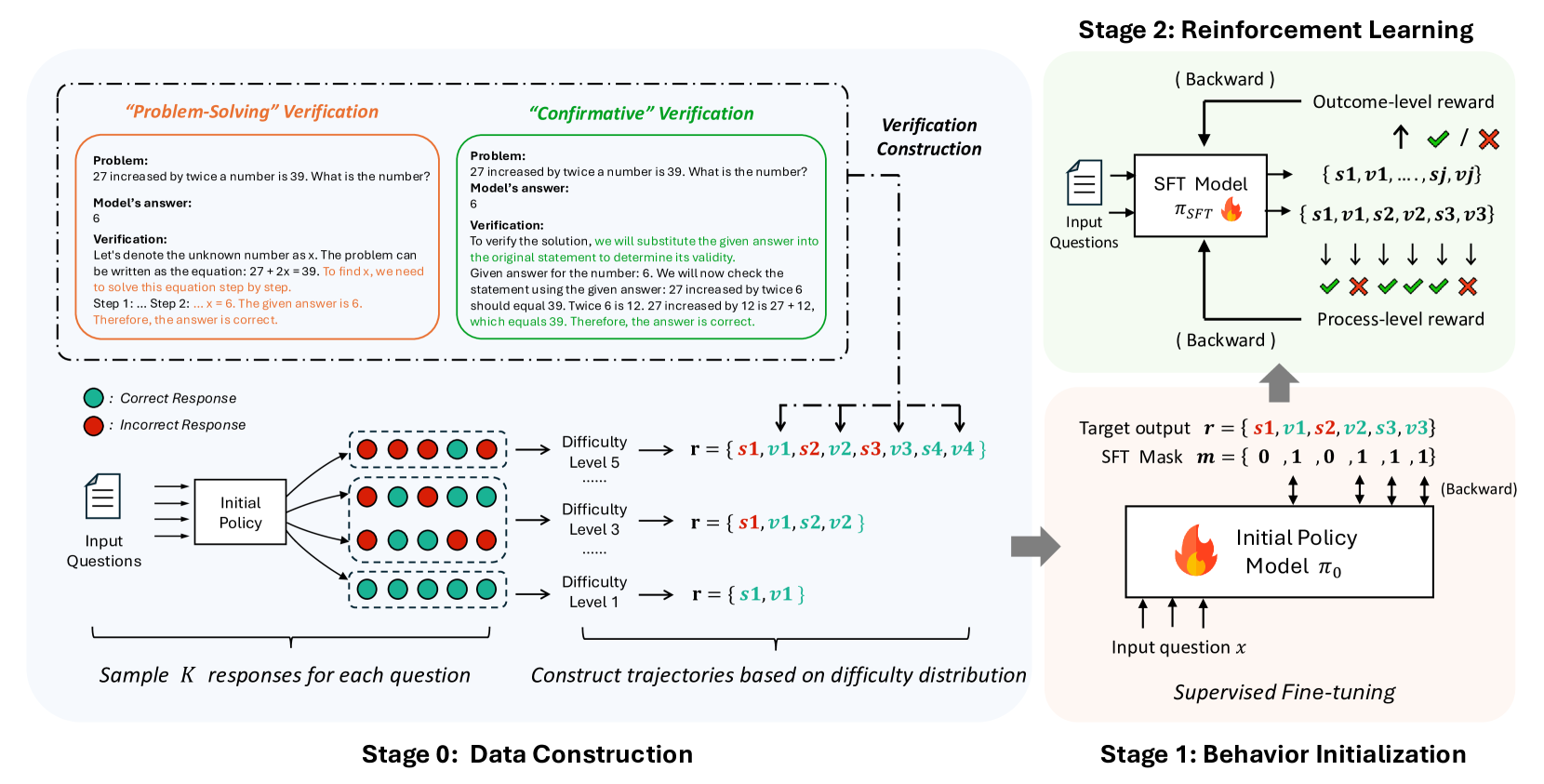
## Diagram: Multi-Stage Training Pipeline for Reasoning Models
### Overview
The image is a technical flowchart illustrating a three-stage pipeline for training a machine learning model to solve reasoning problems. The process begins with **Stage 0: Data Construction**, where training data is generated and verified. This feeds into **Stage 1: Behavior Initialization**, which uses Supervised Fine-Tuning (SFT) to create an initial policy model. Finally, **Stage 2: Reinforcement Learning** refines this model using outcome and process-level rewards. The diagram uses color-coding (green for correct, red for incorrect), flow arrows, and text boxes to detail each step.
### Components/Axes
The diagram is divided into three primary regions, each representing a stage:
1. **Stage 0: Data Construction (Left, light blue background)**
* **Input:** "Input Questions" (document icon).
* **Process:** "Initial Policy" generates multiple responses.
* **Legend:** A green circle denotes ": Correct Response". A red circle denotes ": Incorrect Response".
* **Output:** Responses are grouped by "Difficulty Level" (Level 1, 3, 5) to form reasoning trajectories `r`.
* **Verification Methods:** Two dashed boxes at the top detail verification approaches:
* **"Problem-Solving" Verification (Orange box):** Shows an algebraic problem, a model's answer, and a step-by-step verification solving the equation.
* **"Confirmative" Verification (Green box):** Shows the same problem and answer, but verification substitutes the answer back into the original statement to check its validity.
* **Key Text:** "Sample K responses for each question", "Construct trajectories based on difficulty distribution".
2. **Stage 1: Behavior Initialization (Bottom Right, light pink background)**
* **Title:** "Supervised Fine-tuning".
* **Input:** "Input question x".
* **Model:** "Initial Policy Model π₀" (with a flame icon).
* **Target:** "Target output r = {s1, v1, s2, v2, s3, v3}" and "SFT Mask m = {0, 1, 0, 1, 1, 1}".
* **Flow:** An arrow points from Stage 0's constructed trajectories to this stage. A "(Backward)" arrow indicates gradient flow.
3. **Stage 2: Reinforcement Learning (Top Right, light green background)**
* **Input:** "Input Questions" (document icon) fed into an "SFT Model π_SFT" (with a flame icon).
* **Outputs:** The model generates sequences like `{s1, v1, ..., sj, vj}` and `{s1, v1, s2, v2, s3, v3}`.
* **Rewards:**
* "Outcome-level reward": Indicated by a checkmark (✓) or cross (✗) next to the final answer.
* "Process-level reward": Indicated by a sequence of checkmarks and crosses (✓ ✗ ✓ ✓ ✗) below the model's step-by-step output.
* **Flow:** A "(Backward)" arrow points from the rewards back to the SFT Model. A large grey arrow connects Stage 1 to Stage 2.
### Detailed Analysis
**Stage 0: Data Construction**
* **Verification Example:** The problem is: "27 increased by twice a number is 39. What is the number?" The model's answer is "6".
* *Problem-Solving Verification Text:* "Let's denote the unknown number as x. The problem can be written as the equation: 27 + 2x = 39. To find x, we need to solve this equation step by step. Step 1: ... Step 2: ... x = 6. The given answer is 6. Therefore, the answer is correct."
* *Confirmative Verification Text:* "To verify the solution, we will substitute the given answer into the original statement to determine its validity. Given answer for the number: 6. We will now check the statement using the given answer: 27 increased by twice 6 should equal 39. Twice 6 is 12. 27 increased by 12 is 27 + 12, which equals 39. Therefore, the answer is correct."
* **Trajectory Construction:** For a given question, the Initial Policy samples K responses. These are sorted into difficulty levels.
* Difficulty Level 5: Trajectory `r = {s1, v1, s2, v2, s3, v3, s4, v4}` (8 elements).
* Difficulty Level 3: Trajectory `r = {s1, v1, s2, v2}` (4 elements).
* Difficulty Level 1: Trajectory `r = {s1, v1}` (2 elements).
* The notation `{s, v}` likely represents a "step" and its "verification" or "value".
**Stage 1: Behavior Initialization**
* This stage performs Supervised Fine-Tuning (SFT) on the Initial Policy Model (π₀).
* It uses the constructed trajectories `r` as target outputs.
* The "SFT Mask m = {0, 1, 0, 1, 1, 1}" suggests that only specific parts of the sequence (likely the verification steps `v`) are used for the loss calculation during training.
**Stage 2: Reinforcement Learning**
* The SFT Model (π_SFT) is trained further with RL.
* It receives two types of rewards:
1. **Outcome-level reward:** A single binary signal (✓/✗) for the final answer's correctness.
2. **Process-level reward:** A sequence of binary signals (✓/✗) evaluating the correctness of each intermediate reasoning step.
* Both rewards are used in a "(Backward)" pass to update the model.
### Key Observations
1. **Dual Verification Strategy:** The pipeline employs two distinct methods ("Problem-Solving" and "Confirmative") to verify the correctness of model-generated answers during data construction, ensuring robust labeling.
2. **Difficulty-Aware Data:** Training data is explicitly structured by difficulty level, with more complex problems requiring longer reasoning trajectories (more steps).
3. **Hybrid Reward Structure:** The reinforcement learning stage uses a combination of sparse (outcome) and dense (process-level) rewards, which is a sophisticated approach to guide learning.
4. **Sequential Refinement:** The pipeline shows a clear progression from data generation (Stage 0), to imitation learning (Stage 1), to goal-oriented optimization (Stage 2).
### Interpretation
This diagram outlines a comprehensive methodology for training AI models to perform multi-step reasoning, likely for mathematical or logical problem-solving. The process is designed to overcome key challenges in training such models:
* **Data Scarcity & Quality:** Stage 0 automates the creation of high-quality, verified training data with difficulty annotations, solving the problem of needing large, human-labeled datasets.
* **Learning Stability:** Starting with Supervised Fine-Tuning (Stage 1) on curated trajectories provides a stable behavioral foundation before introducing the more volatile reinforcement learning phase.
* **Credit Assignment:** The use of **process-level rewards** in Stage 2 is particularly significant. It addresses the "credit assignment problem" in long reasoning chains by providing feedback on each step, not just the final answer. This should lead to more reliable and interpretable reasoning patterns.
* **Overall Goal:** The pipeline aims to produce a model that doesn't just arrive at correct answers but does so through a verifiable and correct step-by-step process, enhancing both accuracy and trustworthiness. The "Verification Construction" block linking Stage 0 to the reward signals in Stage 2 indicates that the verification methods developed for data labeling are also used to generate the process-level rewards during RL, creating a cohesive training loop.
DECODING INTELLIGENCE...