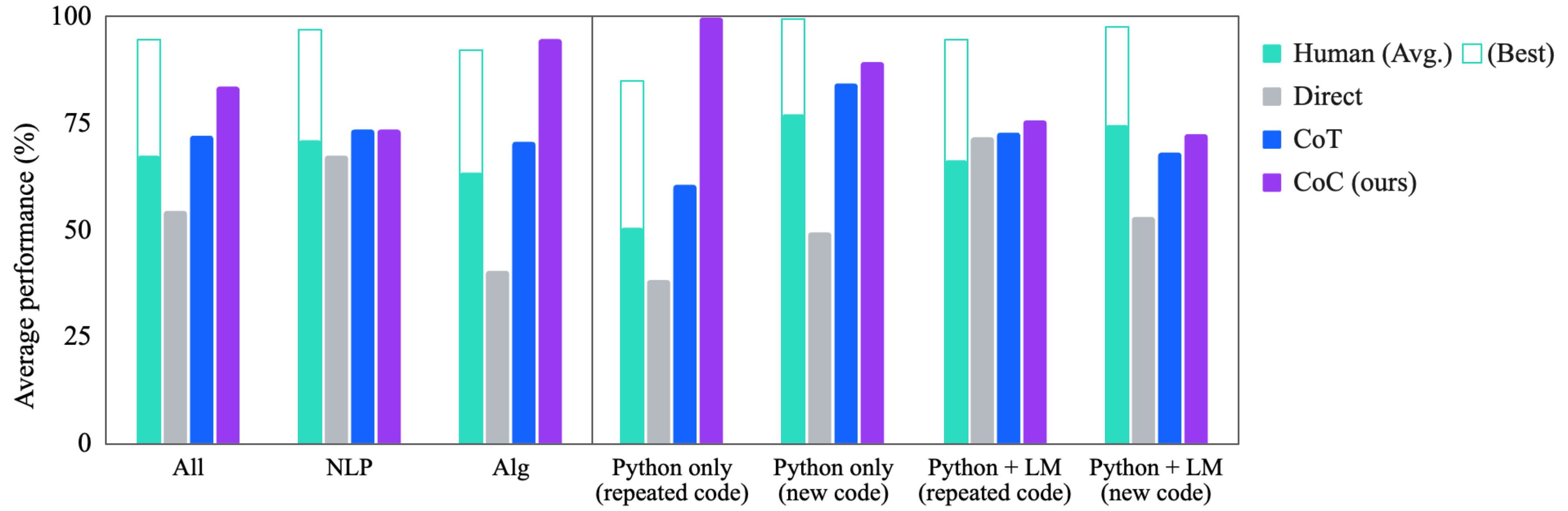
## Grouped Bar Chart: Performance Comparison Across Task Categories
### Overview
The image displays a grouped bar chart comparing the average performance (in percentage) of five different methods or agents across seven distinct task categories. The chart is divided into two sections by a vertical line, suggesting a grouping of the first three categories versus the latter four. The performance metric is on a scale from 0% to 100%.
### Components/Axes
* **Y-Axis:** Labeled "Average performance (%)". The axis has major tick marks at 0, 25, 50, 75, and 100.
* **X-Axis:** Contains seven categorical labels representing different task domains or conditions:
1. All
2. NLP
3. Alg
4. Python only (repeated code)
5. Python only (new code)
6. Python + LM (repeated code)
7. Python + LM (new code)
* **Legend (Top-Right):** Identifies the five data series by color and label:
* **Teal (Solid):** Human (Avg.)
* **Teal (Outline):** (Best) - This appears to represent the best human performance, shown as an outline bar stacked on top of the solid "Human (Avg.)" bar.
* **Gray:** Direct
* **Blue:** CoT
* **Purple:** CoC (ours)
* **Visual Grouping:** A thin vertical line separates the first three categories ("All", "NLP", "Alg") from the last four ("Python only..." and "Python + LM...").
### Detailed Analysis
Below are the approximate performance values for each method in each category, estimated from the bar heights. Values are approximate (±2-3%).
| Category | Human (Avg.) | Human (Best) | Direct | CoT | CoC (ours) |
| :--- | :--- | :--- | :--- | :--- | :--- |
| **All** | ~68% | ~95% | ~54% | ~72% | ~83% |
| **NLP** | ~72% | ~97% | ~68% | ~74% | ~74% |
| **Alg** | ~63% | ~92% | ~40% | ~71% | ~94% |
| **Python only (repeated code)** | ~50% | ~84% | ~38% | ~60% | ~100% |
| **Python only (new code)** | ~77% | ~100% | ~49% | ~83% | ~88% |
| **Python + LM (repeated code)** | ~66% | ~94% | ~72% | ~73% | ~75% |
| **Python + LM (new code)** | ~74% | ~98% | ~53% | ~67% | ~73% |
**Trend Verification per Series:**
* **Human (Avg.):** Performance varies, dipping lowest in "Python only (repeated code)" (~50%) and peaking in "Python only (new code)" (~77%).
* **Direct:** Generally the lowest-performing method across most categories, with a notable exception in "Python + LM (repeated code)" where it is competitive (~72%).
* **CoT:** Shows moderate to strong performance, often between Direct and CoC. It peaks in "Python only (new code)" (~83%).
* **CoC (ours):** Consistently a top performer. It achieves the highest score in the chart (~100% in "Python only (repeated code)") and is the best or tied for best in 5 of the 7 categories.
### Key Observations
1. **CoC Dominance:** The "CoC (ours)" method demonstrates superior or highly competitive performance across nearly all task categories, particularly excelling in algorithmic ("Alg") and Python-related tasks.
2. **Human Performance Gap:** There is a significant gap between average human performance and the best human performance in most categories, especially in "Alg" and "Python only (repeated code)".
3. **Direct Method Weakness:** The "Direct" method is frequently the weakest performer, except in the "Python + LM (repeated code)" category where it matches or slightly exceeds other AI methods.
4. **Task Sensitivity:** Performance for all methods is highly sensitive to the task category. For example, "Python only (repeated code)" shows the widest performance spread (from ~38% to ~100%), while "NLP" shows a much tighter cluster of results.
5. **Code Novelty Impact:** For "Python only" tasks, performance for most methods is notably higher on "new code" compared to "repeated code," with the exception of CoC, which achieves a perfect score on the repeated code task.
### Interpretation
This chart presents a performance benchmark likely from a research paper introducing the "CoC" method. The data suggests that CoC is a robust and generalizable approach, outperforming both a "Direct" prompting baseline and a "CoT" (Chain-of-Thought) method across a diverse set of challenges encompassing natural language processing, algorithms, and programming (both with and without language model assistance).
The inclusion of human performance (average and best) provides crucial context. While the best human performance sets a high ceiling (often near 100%), the average human performance is frequently surpassed by CoC and sometimes by CoT. This indicates that these AI methods are not just matching but can exceed typical human-level performance on these specific benchmark tasks.
The stark difference in results between "repeated code" and "new code" tasks highlights a key evaluation dimension: the ability to generalize versus memorize. CoC's perfect score on "Python only (repeated code)" might suggest strong pattern recognition or memorization, but its continued strong performance on "new code" tasks demonstrates genuine generalization capability. The chart effectively argues for the efficacy of the proposed CoC method relative to common baselines and human performance.