## Diagram: Text Processing Workflow
### Overview
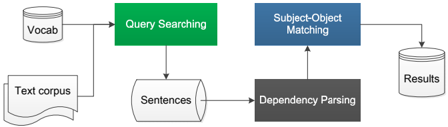
The image is a diagram illustrating a text processing workflow. It shows the flow of data and processes involved in extracting relationships between subjects and objects from a text corpus. The workflow includes steps such as query searching, dependency parsing, and subject-object matching.
### Components/Axes
The diagram consists of the following components:
* **Vocab:** A database-like structure containing vocabulary.
* **Text corpus:** A collection of text documents.
* **Query Searching:** A green rectangular block representing the query searching process.
* **Sentences:** A database-like structure containing sentences extracted from the text corpus.
* **Dependency Parsing:** A dark gray rectangular block representing the dependency parsing process.
* **Subject-Object Matching:** A blue rectangular block representing the subject-object matching process.
* **Results:** A database-like structure containing the results of the subject-object matching.
* **Arrows:** Arrows indicate the flow of data between the components.
### Detailed Analysis or ### Content Details
1. **Vocab** and **Text corpus** feed into **Query Searching**.
2. **Query Searching** outputs to **Sentences**.
3. **Text corpus** also feeds into **Dependency Parsing**.
4. **Sentences** and **Dependency Parsing** feed into **Subject-Object Matching**.
5. **Subject-Object Matching** outputs to **Results**.
### Key Observations
The diagram illustrates a pipeline where a text corpus is processed to extract subject-object relationships. The vocabulary and text corpus are used for query searching, which results in sentences. The text corpus is also used for dependency parsing. The sentences and dependency parsing results are then used for subject-object matching, which produces the final results.
### Interpretation
The diagram represents a typical natural language processing (NLP) pipeline for extracting structured information from unstructured text. The process starts with a text corpus and a vocabulary. Query searching is performed to identify relevant sentences. Dependency parsing is used to analyze the grammatical structure of the sentences. Finally, subject-object matching is performed to extract relationships between subjects and objects. The results of this process can be used for various applications, such as knowledge graph construction, information retrieval, and question answering.