TECHNICAL ASSET FINGERPRINT
e884621714842126f30d3b04
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.5-flash-lite-free VERSION 1
RUNTIME: google-free/gemini-2.5-flash-lite
INTEL_VERIFIED
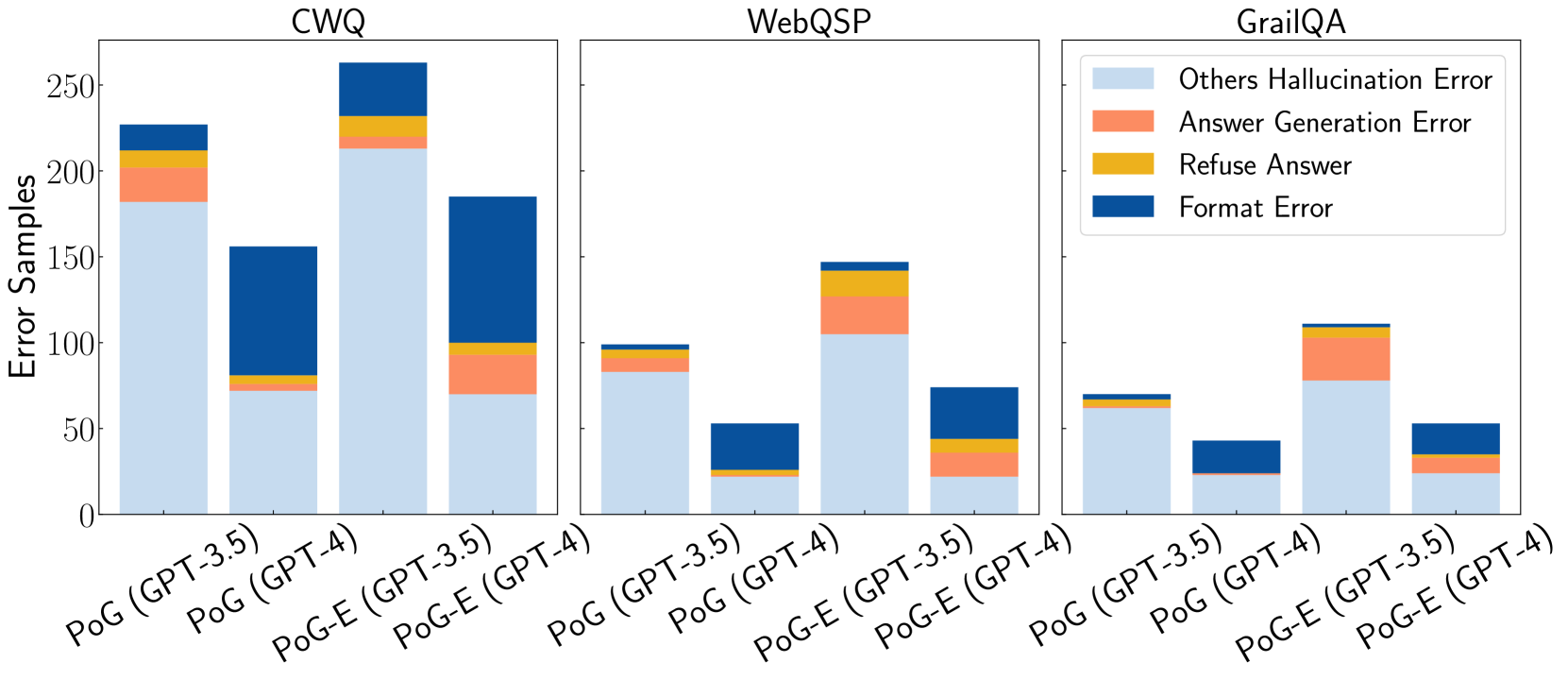
## Stacked Bar Chart: Error Samples by Dataset and Model Configuration
### Overview
This image displays a set of three stacked bar charts, each representing a different dataset: CWQ, WebQSP, and GrailQA. Within each dataset, there are four bars, representing different model configurations: PoG (GPT-3.5), PoG (GPT-4), PoG-E (GPT-3.5), and PoG-E (GPT-4). Each bar is segmented to show the breakdown of error samples into four categories: "Others Hallucination Error", "Answer Generation Error", "Refuse Answer", and "Format Error". The y-axis represents the "Error Samples".
### Components/Axes
**Global Elements:**
* **Y-axis Title:** "Error Samples" (positioned vertically on the left side of the chart area).
* **Y-axis Scale:** Ranges from 0 to 250, with major tick marks at 0, 50, 100, 150, 200, and 250.
* **Legend:** Located in the top-right quadrant of the overall image. It maps colors to error categories:
* Light Blue: "Others Hallucination Error"
* Coral/Light Orange: "Answer Generation Error"
* Yellow/Gold: "Refuse Answer"
* Dark Blue: "Format Error"
**Chart Titles (from left to right):**
1. CWQ
2. WebQSP
3. GrailQA
**X-axis Labels (common across all charts, rotated for readability):**
* PoG (GPT-3.5)
* PoG (GPT-4)
* PoG-E (GPT-3.5)
* PoG-E (GPT-4)
### Detailed Analysis
**Chart 1: CWQ**
* **PoG (GPT-3.5):**
* Others Hallucination Error (light blue): Approximately 175 samples.
* Answer Generation Error (coral): Approximately 25 samples (total ~200).
* Refuse Answer (yellow): Approximately 5 samples (total ~205).
* Format Error (dark blue): Approximately 20 samples (total ~225).
* **Total:** Approximately 225 samples.
* **PoG (GPT-4):**
* Others Hallucination Error (light blue): Approximately 75 samples.
* Answer Generation Error (coral): Approximately 5 samples (total ~80).
* Refuse Answer (yellow): Approximately 0 samples (total ~80).
* Format Error (dark blue): Approximately 75 samples (total ~155).
* **Total:** Approximately 155 samples.
* **PoG-E (GPT-3.5):**
* Others Hallucination Error (light blue): Approximately 210 samples.
* Answer Generation Error (coral): Approximately 15 samples (total ~225).
* Refuse Answer (yellow): Approximately 5 samples (total ~230).
* Format Error (dark blue): Approximately 20 samples (total ~250).
* **Total:** Approximately 250 samples.
* **PoG-E (GPT-4):**
* Others Hallucination Error (light blue): Approximately 85 samples.
* Answer Generation Error (coral): Approximately 5 samples (total ~90).
* Refuse Answer (yellow): Approximately 0 samples (total ~90).
* Format Error (dark blue): Approximately 100 samples (total ~190).
* **Total:** Approximately 190 samples.
**Chart 2: WebQSP**
* **PoG (GPT-3.5):**
* Others Hallucination Error (light blue): Approximately 95 samples.
* Answer Generation Error (coral): Approximately 5 samples (total ~100).
* Refuse Answer (yellow): Approximately 0 samples (total ~100).
* Format Error (dark blue): Approximately 0 samples (total ~100).
* **Total:** Approximately 100 samples.
* **PoG (GPT-4):**
* Others Hallucination Error (light blue): Approximately 20 samples.
* Answer Generation Error (coral): Approximately 0 samples (total ~20).
* Refuse Answer (yellow): Approximately 0 samples (total ~20).
* Format Error (dark blue): Approximately 30 samples (total ~50).
* **Total:** Approximately 50 samples.
* **PoG-E (GPT-3.5):**
* Others Hallucination Error (light blue): Approximately 100 samples.
* Answer Generation Error (coral): Approximately 25 samples (total ~125).
* Refuse Answer (yellow): Approximately 5 samples (total ~130).
* Format Error (dark blue): Approximately 0 samples (total ~130).
* **Total:** Approximately 130 samples.
* **PoG-E (GPT-4):**
* Others Hallucination Error (light blue): Approximately 45 samples.
* Answer Generation Error (coral): Approximately 5 samples (total ~50).
* Refuse Answer (yellow): Approximately 0 samples (total ~50).
* Format Error (dark blue): Approximately 30 samples (total ~80).
* **Total:** Approximately 80 samples.
**Chart 3: GrailQA**
* **PoG (GPT-3.5):**
* Others Hallucination Error (light blue): Approximately 60 samples.
* Answer Generation Error (coral): Approximately 5 samples (total ~65).
* Refuse Answer (yellow): Approximately 0 samples (total ~65).
* Format Error (dark blue): Approximately 0 samples (total ~65).
* **Total:** Approximately 65 samples.
* **PoG (GPT-4):**
* Others Hallucination Error (light blue): Approximately 30 samples.
* Answer Generation Error (coral): Approximately 0 samples (total ~30).
* Refuse Answer (yellow): Approximately 0 samples (total ~30).
* Format Error (dark blue): Approximately 20 samples (total ~50).
* **Total:** Approximately 50 samples.
* **PoG-E (GPT-3.5):**
* Others Hallucination Error (light blue): Approximately 110 samples.
* Answer Generation Error (coral): Approximately 30 samples (total ~140).
* Refuse Answer (yellow): Approximately 5 samples (total ~145).
* Format Error (dark blue): Approximately 0 samples (total ~145).
* **Total:** Approximately 145 samples.
* **PoG-E (GPT-4):**
* Others Hallucination Error (light blue): Approximately 25 samples.
* Answer Generation Error (coral): Approximately 5 samples (total ~30).
* Refuse Answer (yellow): Approximately 0 samples (total ~30).
* Format Error (dark blue): Approximately 25 samples (total ~55).
* **Total:** Approximately 55 samples.
### Key Observations
* **Dominant Error Type:** Across all datasets and configurations, "Others Hallucination Error" (light blue) is consistently the largest component of the total error samples.
* **Dataset Variation:** The total number of error samples varies significantly by dataset. CWQ generally shows the highest total error samples, followed by WebQSP and then GrailQA.
* **Model Configuration Impact:**
* Within each dataset, the "PoG-E (GPT-3.5)" configuration often exhibits a higher total number of error samples compared to "PoG (GPT-3.5)".
* The "GPT-4" models ("PoG (GPT-4)" and "PoG-E (GPT-4)") generally show fewer total error samples than their GPT-3.5 counterparts, particularly in the CWQ and WebQSP datasets.
* **Format Error:** "Format Error" (dark blue) is a significant contributor in some specific cases, notably for "PoG (GPT-4)" in CWQ and WebQSP, and "PoG-E (GPT-4)" in GrailQA.
* **Refuse Answer and Answer Generation Error:** These categories ("Refuse Answer" - yellow, "Answer Generation Error" - coral) are generally much smaller components of the total errors, often appearing as thin slices or being absent in many bars.
### Interpretation
This chart visually demonstrates the error distribution across different datasets and model configurations. The data suggests that:
1. **Hallucination is a Pervasive Issue:** The consistent dominance of "Others Hallucination Error" indicates that generating factually incorrect or fabricated information is a primary challenge for these models, regardless of the dataset or specific configuration. This points to a fundamental limitation in their knowledge grounding or reasoning capabilities.
2. **Dataset Complexity and Model Performance:** The variation in total error samples across datasets (CWQ > WebQSP > GrailQA) implies that the complexity or nature of the questions in these datasets impacts model performance. CWQ, with the highest errors, might pose more challenging reasoning or knowledge retrieval tasks.
3. **GPT-4's Potential Improvement:** The trend of lower total errors for GPT-4 models compared to GPT-3.5 models, especially in CWQ and WebQSP, suggests that GPT-4 offers an improvement in reducing overall errors. This could be attributed to enhanced reasoning, better knowledge recall, or improved generation capabilities.
4. **Configuration-Specific Trade-offs:** The "PoG-E" configuration, while sometimes leading to higher total errors with GPT-3.5, might be designed for different objectives or have different architectural properties that influence error types. The data suggests that "PoG-E (GPT-3.5)" might be more prone to hallucination or other errors than the base "PoG (GPT-3.5)".
5. **Specific Error Bottlenecks:** The presence of significant "Format Error" in certain configurations (e.g., PoG (GPT-4) in CWQ) highlights that while GPT-4 might reduce general errors, specific issues like output formatting can still be problematic depending on the task and model. The relative scarcity of "Refuse Answer" and "Answer Generation Error" suggests these are less common failure modes compared to hallucination.
In essence, the chart provides a comparative analysis of model robustness and error profiles. It underscores the ongoing challenge of factual accuracy (hallucination) in large language models and highlights the potential benefits of newer model versions (GPT-4) and specific configurations in mitigating these issues, while also revealing dataset-dependent performance variations.
DECODING INTELLIGENCE...