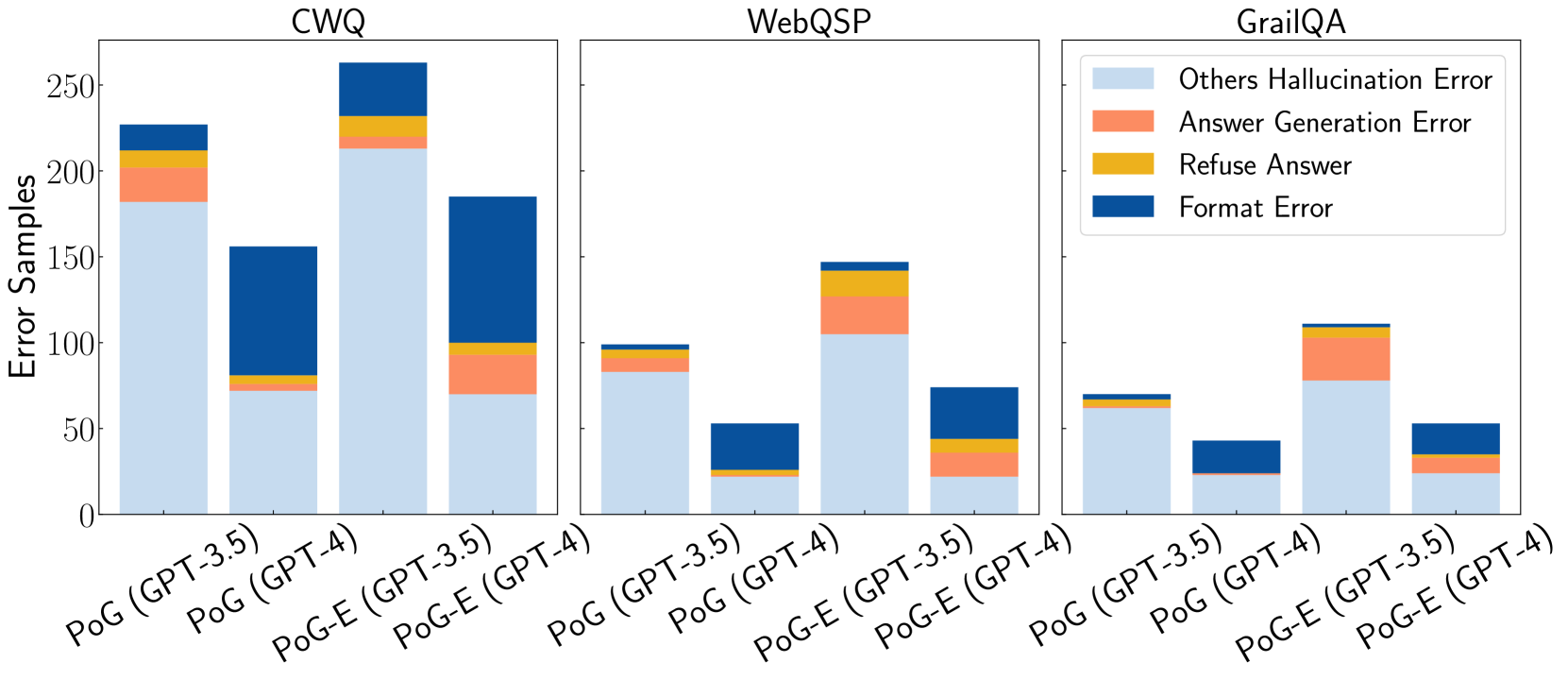
## Stacked Bar Chart: Error Analysis Across Three QA Datasets
### Overview
The image displays three separate stacked bar charts arranged horizontally, comparing the distribution of error types for four different model configurations across three question-answering (QA) datasets: CWQ, WebQSP, and GrailQA. The y-axis for all charts is labeled "Error Samples," indicating the count of erroneous responses. Each chart contains four bars, representing two base methods (PoG and PoG-E) each run with two underlying language models (GPT-3.5 and GPT-4).
### Components/Axes
* **Chart Titles (Top Center):** "CWQ", "WebQSP", "GrailQA"
* **Y-Axis Label (Left Side, Shared):** "Error Samples"
* **Y-Axis Scale:** Linear scale from 0 to 250, with major ticks at 0, 50, 100, 150, 200, 250.
* **X-Axis Labels (Bottom of each chart):** Four categories per chart:
1. `PoG (GPT-3.5)`
2. `PoG (GPT-4)`
3. `PoG-E (GPT-3.5)`
4. `PoG-E (GPT-4)`
* **Legend (Top Right of the GrailQA chart):** A box containing four colored squares with corresponding labels:
* Light Blue: `Others Hallucination Error`
* Orange: `Answer Generation Error`
* Yellow: `Refuse Answer`
* Dark Blue: `Format Error`
### Detailed Analysis
**1. CWQ Chart (Leftmost)**
* **Trend:** The total error count is highest for the PoG-E (GPT-3.5) configuration. The PoG (GPT-4) configuration shows a notably different error composition, with a very large "Format Error" segment.
* **Data Points (Approximate Values):**
* **PoG (GPT-3.5):** Total ~225. Others Hallucination: ~180. Answer Generation: ~25. Refuse Answer: ~10. Format Error: ~10.
* **PoG (GPT-4):** Total ~155. Others Hallucination: ~75. Answer Generation: ~5. Refuse Answer: ~5. Format Error: ~70.
* **PoG-E (GPT-3.5):** Total ~260. Others Hallucination: ~215. Answer Generation: ~15. Refuse Answer: ~10. Format Error: ~20.
* **PoG-E (GPT-4):** Total ~185. Others Hallucination: ~70. Answer Generation: ~25. Refuse Answer: ~5. Format Error: ~85.
**2. WebQSP Chart (Center)**
* **Trend:** Overall error counts are lower than in CWQ. The PoG-E (GPT-3.5) configuration again has the highest total errors. The "Format Error" segment is prominent in the GPT-4 based models.
* **Data Points (Approximate Values):**
* **PoG (GPT-3.5):** Total ~100. Others Hallucination: ~85. Answer Generation: ~10. Refuse Answer: ~3. Format Error: ~2.
* **PoG (GPT-4):** Total ~55. Others Hallucination: ~25. Answer Generation: ~2. Refuse Answer: ~3. Format Error: ~25.
* **PoG-E (GPT-3.5):** Total ~145. Others Hallucination: ~105. Answer Generation: ~25. Refuse Answer: ~10. Format Error: ~5.
* **PoG-E (GPT-4):** Total ~75. Others Hallucination: ~25. Answer Generation: ~15. Refuse Answer: ~5. Format Error: ~30.
**3. GrailQA Chart (Rightmost)**
* **Trend:** This dataset shows the lowest overall error counts. The pattern of PoG-E (GPT-3.5) having the most errors and GPT-4 models having larger "Format Error" segments continues.
* **Data Points (Approximate Values):**
* **PoG (GPT-3.5):** Total ~70. Others Hallucination: ~60. Answer Generation: ~5. Refuse Answer: ~3. Format Error: ~2.
* **PoG (GPT-4):** Total ~45. Others Hallucination: ~25. Answer Generation: ~2. Refuse Answer: ~1. Format Error: ~17.
* **PoG-E (GPT-3.5):** Total ~110. Others Hallucination: ~75. Answer Generation: ~25. Refuse Answer: ~5. Format Error: ~5.
* **PoG-E (GPT-4):** Total ~55. Others Hallucination: ~25. Answer Generation: ~10. Refuse Answer: ~3. Format Error: ~17.
### Key Observations
1. **Dominant Error Type:** "Others Hallucination Error" (light blue) is consistently the largest error component across all datasets and models, especially for GPT-3.5 based configurations.
2. **Model Comparison:** GPT-4 based models (`PoG (GPT-4)` and `PoG-E (GPT-4)`) consistently show a much larger proportion of "Format Error" (dark blue) compared to their GPT-3.5 counterparts.
3. **Method Comparison:** The `PoG-E` method generally results in a higher total number of error samples than the `PoG` method when using the same underlying language model (GPT-3.5 or GPT-4).
4. **Dataset Difficulty:** The total error counts are highest for CWQ, intermediate for WebQSP, and lowest for GrailQA, suggesting varying levels of difficulty or error propensity across these benchmarks for the tested models.
### Interpretation
This visualization provides a diagnostic breakdown of *why* models fail on these QA tasks, moving beyond simple accuracy metrics. The data suggests two key insights:
1. **Hallucination is the Primary Failure Mode:** The overwhelming prevalence of "Others Hallucination Error" indicates that the core challenge for these models is generating factually incorrect or unsupported information, rather than refusing to answer or making simple formatting mistakes.
2. **Model Capability Affects Error Type:** The shift from hallucination-dominated errors in GPT-3.5 to a significant share of format errors in GPT-4 implies that as models become more capable (GPT-4), they may be better at avoiding factual hallucinations but encounter new failures in adhering to strict output protocols or structured response formats required by the evaluation framework. This highlights a potential trade-off or a new area for refinement in more advanced models.
The consistent pattern across three distinct datasets strengthens the reliability of these observations. The `PoG-E` method, while potentially offering other benefits, appears to increase the raw number of errors, particularly hallucinations, compared to the base `PoG` method.