\n
## Heatmap: Model Performance Comparison
### Overview
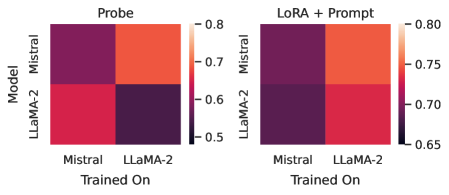
The image presents two heatmaps side-by-side, comparing the performance of two language models – Mistral and LLaMA-2 – under two different training conditions: "Probe" and "LoRA + Prompt". The heatmaps visualize a metric (likely a correlation or similarity score) based on which model was trained on which dataset. The color intensity represents the value of the metric, with darker colors indicating lower values and lighter colors indicating higher values.
### Components/Axes
* **Y-axis (Vertical):** "Model" with categories: Mistral, LLaMA-2.
* **X-axis (Horizontal):** "Trained On" with categories: Mistral, LLaMA-2.
* **Color Scale (Right):** Ranges from approximately 0.65 (dark purple) to 0.80 (light orange).
* **Titles:** "Probe" (left heatmap), "LoRA + Prompt" (right heatmap).
* **Legend:** A color gradient is provided on the right side of both heatmaps, indicating the mapping between color and metric value.
### Detailed Analysis or Content Details
**Heatmap 1: Probe**
* **Mistral / Mistral:** Approximately 0.78 (orange).
* **Mistral / LLaMA-2:** Approximately 0.68 (red).
* **LLaMA-2 / Mistral:** Approximately 0.67 (red).
* **LLaMA-2 / LLaMA-2:** Approximately 0.55 (dark purple).
**Heatmap 2: LoRA + Prompt**
* **Mistral / Mistral:** Approximately 0.79 (orange).
* **Mistral / LLaMA-2:** Approximately 0.72 (red).
* **LLaMA-2 / Mistral:** Approximately 0.73 (red).
* **LLaMA-2 / LLaMA-2:** Approximately 0.68 (red).
### Key Observations
* In both heatmaps, training a model on its own dataset (Mistral on Mistral, LLaMA-2 on LLaMA-2) yields the highest metric values.
* The "Probe" heatmap shows a more pronounced difference between training on the same dataset versus a different dataset. The LLaMA-2 model trained on LLaMA-2 has a significantly lower value (0.55) compared to the other values.
* The "LoRA + Prompt" heatmap shows less variation. The values are generally higher, and the difference between training on the same vs. different datasets is less dramatic.
* Mistral consistently performs better than LLaMA-2 when trained on LLaMA-2 data, in both training conditions.
### Interpretation
The data suggests that both models perform best when trained on data from the same distribution as their pre-training data. The "Probe" heatmap indicates a stronger dependency on this alignment for LLaMA-2, as its performance drops significantly when trained on Mistral data. The "LoRA + Prompt" method appears to mitigate this dependency to some extent, as the performance difference between training on the same vs. different datasets is smaller.
The higher values in the "LoRA + Prompt" heatmap overall suggest that this training method is more effective at generalizing across datasets or adapting to different data distributions. The LoRA (Low-Rank Adaptation) technique, combined with prompt engineering, likely allows the models to better leverage information from datasets different from their original training data.
The difference in performance between the two models when trained on the other model's data could indicate differences in their architectures or pre-training objectives. Mistral's ability to maintain relatively higher performance when trained on LLaMA-2 data suggests it may be more robust or adaptable.