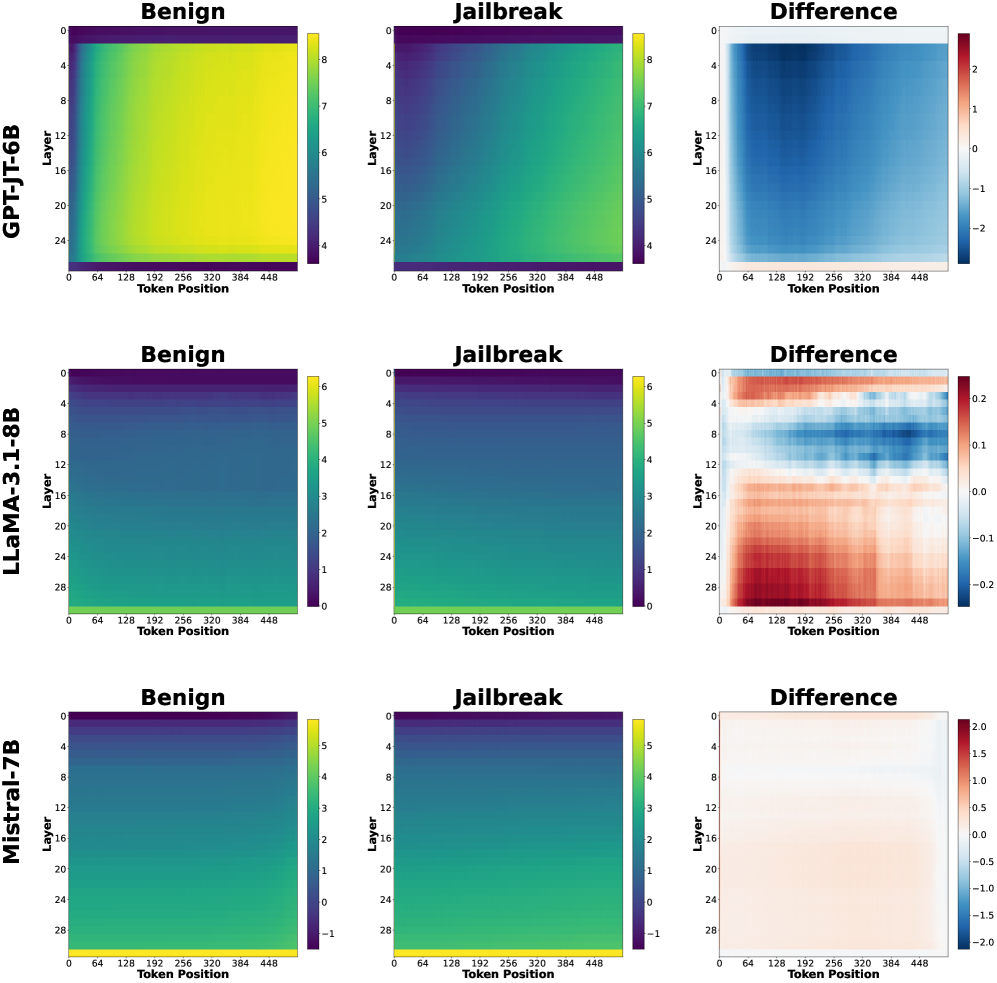
## Heatmap Analysis: Model Behavior Comparison Across Scenarios
### Overview
The image presents a comparative analysis of three language models (GPT-JT-6B, LLaMA-3.1-8B, Mistral-7B) across three scenarios: **Benign**, **Jailbreak**, and **Difference**. Each model is represented by three heatmaps showing values across **Layers** (vertical axis) and **Token Positions** (horizontal axis). Color gradients indicate magnitude, with legends specifying value ranges.
---
### Components/Axes
1. **Models**:
- GPT-JT-6B (top row)
- LLaMA-3.1-8B (middle row)
- Mistral-7B (bottom row)
2. **Panels per Model**:
- **Benign**: Baseline behavior
- **Jailbreak**: Modified/stressed behavior
- **Difference**: Absolute difference between Benign and Jailbreak
3. **Axes**:
- **Vertical (Y-axis)**: Layers (0–28, incrementing by 4)
- **Horizontal (X-axis)**: Token Positions (0–448, incrementing by 64)
4. **Legends**:
- Right-aligned colorbars with value ranges:
- GPT-JT-6B: 4–8 (Benign), 4–8 (Jailbreak), -2–2 (Difference)
- LLaMA-3.1-8B: 0–6 (Benign), 0–6 (Jailbreak), -2–2 (Difference)
- Mistral-7B: -1–5 (Benign), -1–5 (Jailbreak), -2–2 (Difference)
---
### Detailed Analysis
#### GPT-JT-6B
- **Benign**: Uniform yellow gradient (values ~7–8 across all layers/tokens).
- **Jailbreak**: Green gradient (values ~4–6), indicating reduced activity.
- **Difference**: Blue gradient (values ~-2 to 0), showing consistent decline in Jailbreak.
#### LLaMA-3.1-8B
- **Benign**: Dark blue gradient (values ~0–3), lower baseline than GPT-JT-6B.
- **Jailbreak**: Lighter blue gradient (values ~3–6), moderate increase.
- **Difference**: Mixed red/blue regions (values ~-1 to +1), indicating variable layer/token sensitivity.
#### Mistral-7B
- **Benign**: Green gradient (values ~1–4), moderate baseline.
- **Jailbreak**: Darker blue gradient (values ~-1–2), slight decline.
- **Difference**: Neutral gradient (values ~-0.5 to +0.5), minimal changes.
---
### Key Observations
1. **GPT-JT-6B**:
- Highest baseline values in Benign (yellow).
- Sharp drop in Jailbreak (green), with uniform decline across all layers/tokens.
- Difference heatmap shows consistent negative values (-2 to 0), suggesting jailbreak reduces performance.
2. **LLaMA-3.1-8B**:
- Lower baseline (dark blue) but notable variability in Jailbreak (lighter blue).
- Difference heatmap reveals red regions (positive values) in lower layers (0–12), indicating some layers improve under jailbreak.
3. **Mistral-7B**:
- Most stable performance: minimal difference between scenarios.
- Difference heatmap is nearly neutral, with slight red in lower layers (0–8).
---
### Interpretation
- **Model Robustness**:
- GPT-JT-6B exhibits the largest performance drop under jailbreak, suggesting vulnerability.
- Mistral-7B shows the least sensitivity to jailbreak, indicating robustness.
- **Layer-Specific Behavior**:
- LLaMA-3.1-8B’s red regions in Difference (layers 0–12) imply lower layers may adapt better to jailbreak prompts.
- GPT-JT-6B’s uniform decline suggests systemic sensitivity across all layers.
- **Token Position Impact**:
- No clear token-position trends in Difference heatmaps, indicating effects are layer-dependent rather than position-dependent.
---
### Critical Insights
- **Jailbreak Impact**:
- GPT-JT-6B’s uniform decline (-2 to 0) suggests jailbreak uniformly degrades performance.
- LLaMA-3.1-8B’s mixed red/blue Difference regions highlight layer-specific vulnerabilities.
- **Design Implications**:
- Models with higher baseline values (GPT-JT-6B) may require stricter safeguards.
- Mistral-7B’s stability could make it preferable for safety-critical applications.
---
### Uncertainties
- Exact numerical values are approximated from color gradients; precise thresholds require raw data.
- Token-position trends are ambiguous due to uniform coloration in Difference heatmaps.