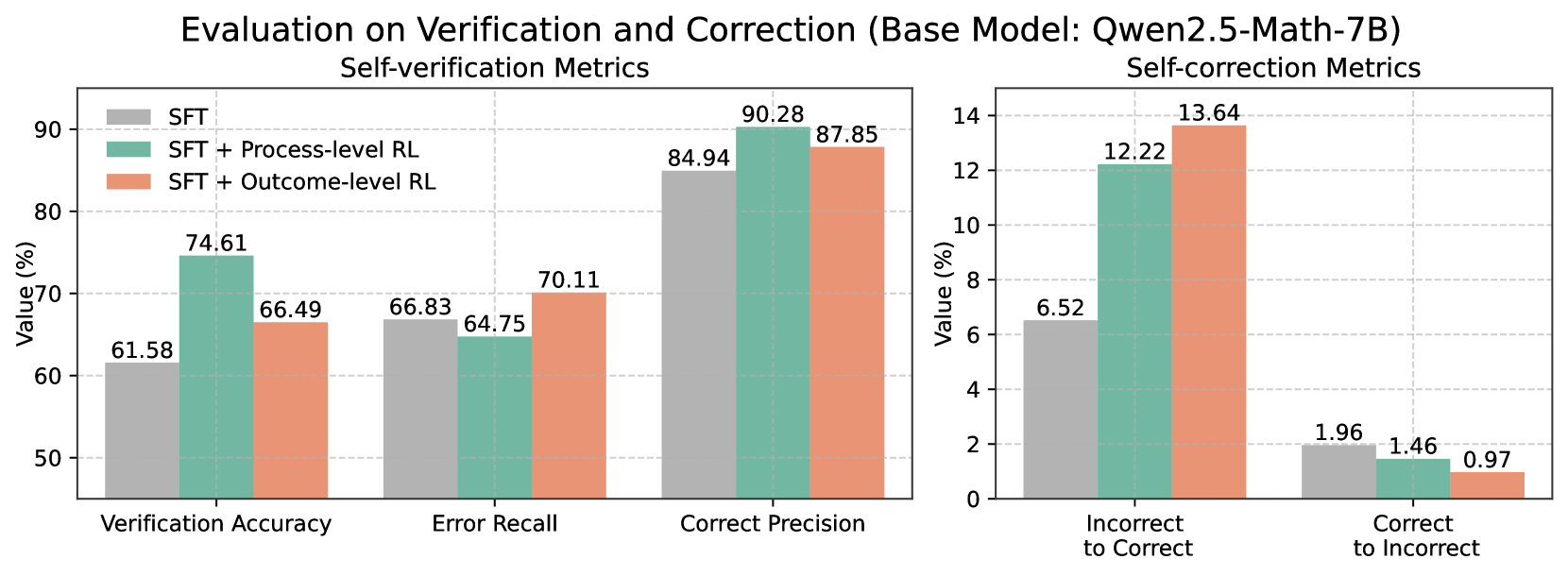
## Bar Chart: Evaluation on Verification and Correction (Base Model: Qwen2.5-Math-7B)
### Overview
The image is a composite bar chart comparing the performance of three different training methods on a base language model (Qwen2.5-Math-7B) across two sets of metrics: "Self-verification Metrics" and "Self-correction Metrics." The chart evaluates how well the model can verify its own outputs and correct errors.
### Components/Axes
* **Title:** "Evaluation on Verification and Correction (Base Model: Qwen2.5-Math-7B)"
* **Subplots:** The chart is divided into two distinct panels.
* **Left Panel Title:** "Self-verification Metrics"
* **Right Panel Title:** "Self-correction Metrics"
* **Legend:** Located in the top-left corner of the left panel. It defines three data series:
* **SFT** (Gray bar)
* **SFT + Process-level RL** (Teal/Green bar)
* **SFT + Outcome-level RL** (Salmon/Orange bar)
* **Y-Axis (Left Panel):** Labeled "Value (%)". Scale ranges from 50 to 90, with major gridlines at intervals of 10.
* **X-Axis (Left Panel):** Three categorical groups:
1. Verification Accuracy
2. Error Recall
3. Correct Precision
* **Y-Axis (Right Panel):** Labeled "Value (%)". Scale ranges from 0 to 14, with major gridlines at intervals of 2.
* **X-Axis (Right Panel):** Two categorical groups:
1. Incorrect to Correct
2. Correct to Incorrect
### Detailed Analysis
**Self-verification Metrics (Left Panel):**
1. **Verification Accuracy:**
* **SFT:** 61.58%
* **SFT + Process-level RL:** 74.61% (Highest in this group)
* **SFT + Outcome-level RL:** 66.49%
* *Trend:* Process-level RL provides the largest improvement over the SFT baseline, followed by Outcome-level RL.
2. **Error Recall:**
* **SFT:** 66.83%
* **SFT + Process-level RL:** 64.75% (Lowest in this group)
* **SFT + Outcome-level RL:** 70.11% (Highest in this group)
* *Trend:* Outcome-level RL improves error recall over SFT, while Process-level RL slightly decreases it.
3. **Correct Precision:**
* **SFT:** 84.94%
* **SFT + Process-level RL:** 90.28% (Highest in this group)
* **SFT + Outcome-level RL:** 87.85%
* *Trend:* Both RL methods improve precision, with Process-level RL showing the greatest gain.
**Self-correction Metrics (Right Panel):**
1. **Incorrect to Correct (Rate of fixing wrong answers):**
* **SFT:** 6.52%
* **SFT + Process-level RL:** 12.22%
* **SFT + Outcome-level RL:** 13.64% (Highest in this group)
* *Trend:* Both RL methods nearly double or more than double the self-correction rate compared to SFT, with Outcome-level RL performing best.
2. **Correct to Incorrect (Rate of breaking right answers):**
* **SFT:** 1.96%
* **SFT + Process-level RL:** 1.46%
* **SFT + Outcome-level RL:** 0.97% (Lowest in this group)
* *Trend:* Both RL methods reduce the rate of corrupting correct answers, with Outcome-level RL showing the most significant reduction.
### Key Observations
* **Performance Trade-offs:** The two RL methods show complementary strengths. "SFT + Process-level RL" excels in Verification Accuracy and Correct Precision. "SFT + Outcome-level RL" excels in Error Recall and the "Incorrect to Correct" self-correction rate.
* **Consistent Improvement in Correction:** Both RL methods dramatically improve the model's ability to correct its own errors ("Incorrect to Correct") while simultaneously reducing its tendency to alter correct answers ("Correct to Incorrect").
* **Baseline Performance:** The SFT (Supervised Fine-Tuning) baseline serves as the reference point, with all RL variants showing targeted improvements in specific metrics.
### Interpretation
This data suggests that applying Reinforcement Learning (RL) to a math-capable language model enhances its metacognitive abilities—specifically, its capacity to self-verify and self-correct its reasoning. The choice of RL objective creates a specialisation:
* **Process-level RL** (which likely rewards intermediate reasoning steps) appears to make the model more precise and accurate in its verification judgments, leading to higher confidence when it identifies a correct answer.
* **Outcome-level RL** (which rewards only the final answer) seems to make the model more sensitive to errors, improving its recall of mistakes and its ability to transform incorrect solutions into correct ones.
The most significant practical takeaway is the substantial reduction in the "Correct to Incorrect" rate alongside the increase in "Incorrect to Correct" rate. This indicates the RL-trained models are not just guessing more often but are becoming more reliable self-editors, a crucial trait for autonomous problem-solving systems. The base model, Qwen2.5-Math-7B, demonstrates a strong foundation that is meaningfully enhanced by these targeted training strategies.