\n
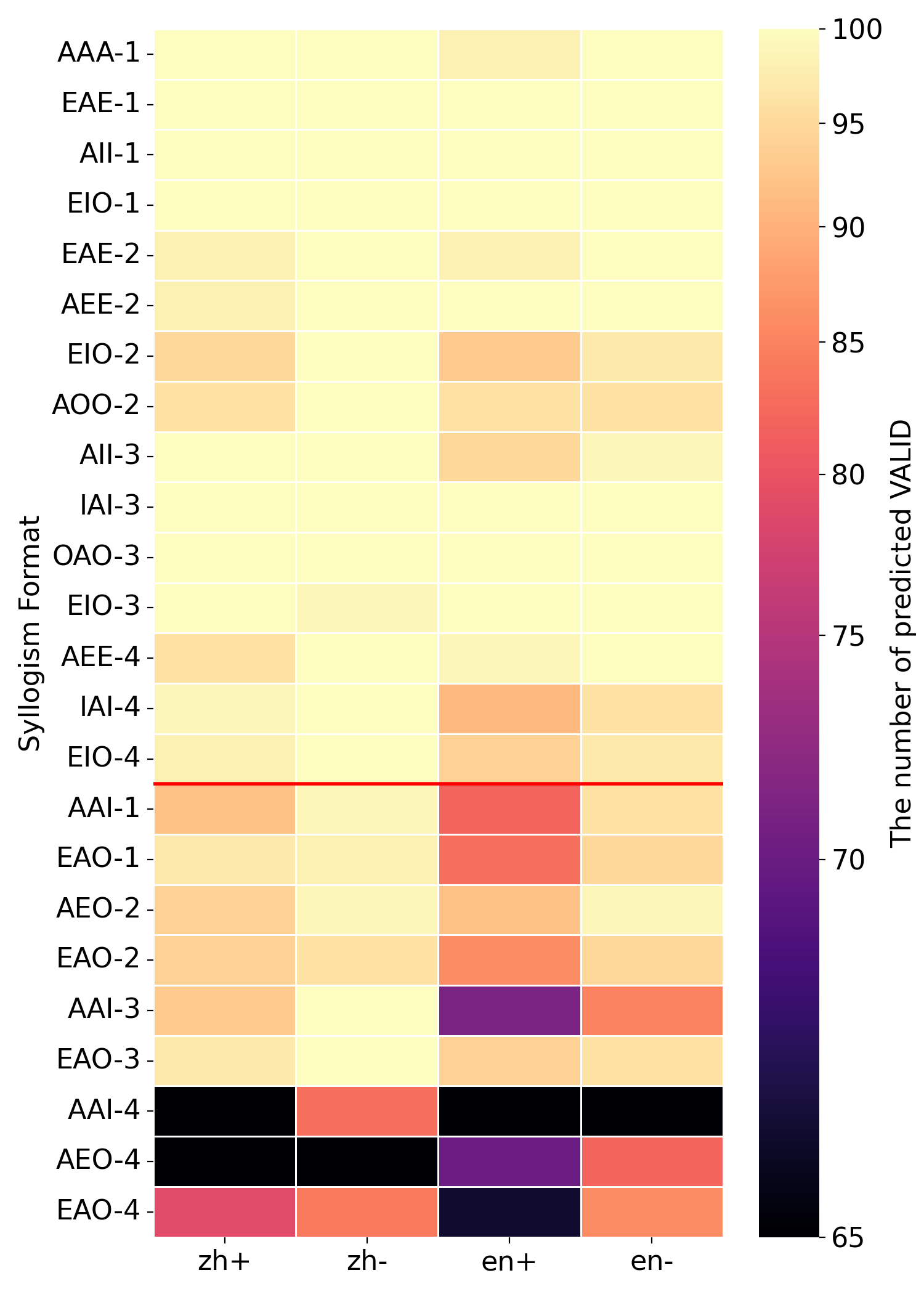
## Heatmap: Syllogism Format Performance
### Overview
This image presents a heatmap visualizing the performance of a system (likely a natural language processing model) in predicting the validity of syllogisms. The heatmap displays the number of predicted valid syllogisms for different syllogism formats, categorized by language (Chinese and English) and polarity (positive and negative).
### Components/Axes
* **Y-axis:** "Syllogism Format" - Lists 24 different syllogism formats. These formats are labeled as AAA-1, EAE-1, AII-1, EIO-1, EAE-2, AEE-2, EIO-2, AOO-2, AII-3, IAI-3, OAO-3, EIO-3, AEE-4, IAI-4, EIO-4, AAI-1, EAO-1, AEO-2, EAO-2, AAI-3, EAO-3, AAI-4, AEO-4, EAO-4.
* **X-axis:** Language and Polarity - Four categories: "zh+", "zh-", "en+", "en-". "zh" likely represents Chinese, and "en" represents English. "+" and "-" likely denote positive and negative polarity, respectively.
* **Color Scale:** A gradient scale on the right side of the heatmap represents "The number of predicted VALID". The scale ranges from approximately 65 (dark purple) to 100 (light yellow).
* **Legend:** The color scale acts as the legend, mapping color intensity to the number of predicted valid syllogisms.
### Detailed Analysis
The heatmap shows the number of predicted valid syllogisms for each combination of syllogism format and language/polarity. The values are represented by color intensity, with darker colors indicating lower counts and lighter colors indicating higher counts.
Here's a breakdown of approximate values, reading from left to right and top to bottom:
* **zh+:**
* AAA-1: ~98
* EAE-1: ~97
* AII-1: ~96
* EIO-1: ~95
* EAE-2: ~94
* AEE-2: ~93
* EIO-2: ~92
* AOO-2: ~91
* AII-3: ~89
* IAI-3: ~88
* OAO-3: ~87
* EIO-3: ~86
* AEE-4: ~84
* IAI-4: ~83
* EIO-4: ~82
* AAI-1: ~79
* EAO-1: ~78
* AEO-2: ~77
* EAO-2: ~76
* AAI-3: ~74
* EAO-3: ~73
* AAI-4: ~71
* AEO-4: ~70
* EAO-4: ~68
* **zh-:**
* AAA-1: ~96
* EAE-1: ~95
* AII-1: ~94
* EIO-1: ~93
* EAE-2: ~92
* AEE-2: ~91
* EIO-2: ~90
* AOO-2: ~89
* AII-3: ~87
* IAI-3: ~86
* OAO-3: ~85
* EIO-3: ~84
* AEE-4: ~82
* IAI-4: ~81
* EIO-4: ~80
* AAI-1: ~77
* EAO-1: ~76
* AEO-2: ~75
* EAO-2: ~74
* AAI-3: ~72
* EAO-3: ~71
* AAI-4: ~69
* AEO-4: ~68
* EAO-4: ~66
* **en+:**
* AAA-1: ~99
* EAE-1: ~98
* AII-1: ~97
* EIO-1: ~96
* EAE-2: ~95
* AEE-2: ~94
* EIO-2: ~93
* AOO-2: ~92
* AII-3: ~90
* IAI-3: ~89
* OAO-3: ~88
* EIO-3: ~87
* AEE-4: ~85
* IAI-4: ~84
* EIO-4: ~83
* AAI-1: ~80
* EAO-1: ~79
* AEO-2: ~78
* EAO-2: ~77
* AAI-3: ~75
* EAO-3: ~74
* AAI-4: ~72
* AEO-4: ~71
* EAO-4: ~69
* **en-:**
* AAA-1: ~97
* EAE-1: ~96
* AII-1: ~95
* EIO-1: ~94
* EAE-2: ~93
* AEE-2: ~92
* EIO-2: ~91
* AOO-2: ~90
* AII-3: ~88
* IAI-3: ~87
* OAO-3: ~86
* EIO-3: ~85
* AEE-4: ~83
* IAI-4: ~82
* EIO-4: ~81
* AAI-1: ~78
* EAO-1: ~77
* AEO-2: ~76
* EAO-2: ~75
* AAI-3: ~73
* EAO-3: ~72
* AAI-4: ~70
* AEO-4: ~69
* EAO-4: ~67
### Key Observations
* Generally, performance is higher for positive polarity ("zh+" and "en+") compared to negative polarity ("zh-" and "en-").
* English (both "+" and "-") consistently shows slightly higher performance than Chinese.
* The syllogism formats AAA-1, EAE-1, and AII-1 consistently receive the highest predicted validity scores across all language/polarity combinations.
* The syllogism formats AAI-4, AEO-4, and EAO-4 consistently receive the lowest predicted validity scores.
* There is a clear trend of decreasing performance as the syllogism format number increases (e.g., moving from AAA-1 to AAA-4).
### Interpretation
The heatmap suggests that the system is more accurate at identifying valid syllogisms in English than in Chinese, and it performs better with positive polarity syllogisms. The varying performance across different syllogism formats indicates that the system's ability to assess validity is sensitive to the specific logical structure of the syllogism. The lower scores for formats like AAI-4, AEO-4, and EAO-4 might indicate that these formats are more challenging for the system to process, potentially due to their complexity or ambiguity.
The data suggests that the system has learned to associate certain syllogism formats with validity more strongly than others. This could be due to biases in the training data or inherent differences in the logical properties of the formats. The difference in performance between positive and negative polarity could be related to the way the system handles negation or the distribution of positive and negative examples in the training data. Further investigation into the training data and the system's internal representations would be needed to understand these patterns more fully.