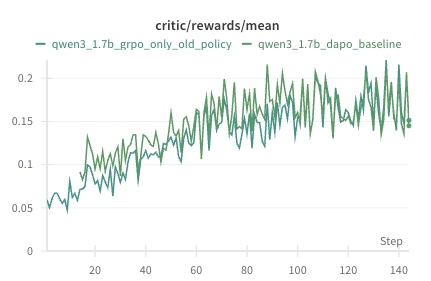
## Line Chart: critic/rewards/mean
### Overview
The image is a line chart comparing the performance of two models, "qwen3_1.7b_grpo_only_old_policy" and "qwen3_1.7b_dapo_baseline", based on the metric "critic/rewards/mean" over a series of steps. Both lines show an upward trend, indicating increasing rewards as the steps progress.
### Components/Axes
* **Title:** critic/rewards/mean
* **X-axis:** Step, with markers at 0, 20, 40, 60, 80, 100, 120, and 140.
* **Y-axis:** Numerical values ranging from 0 to 0.25, with markers at 0, 0.05, 0.1, 0.15, and 0.2.
* **Legend:** Located at the top of the chart.
* **Green-Blue Line:** qwen3\_1.7b\_grpo\_only\_old\_policy
* **Green Line:** qwen3\_1.7b\_dapo\_baseline
### Detailed Analysis
* **qwen3\_1.7b\_grpo\_only\_old\_policy (Green-Blue Line):**
* The line starts at approximately 0.05 at Step 0.
* It generally slopes upward, reaching approximately 0.15-0.2 at Step 140.
* The line exhibits fluctuations, indicating variability in the rewards at each step.
* **qwen3\_1.7b\_dapo\_baseline (Green Line):**
* The line starts at approximately 0.06 at Step 0.
* It also generally slopes upward, reaching approximately 0.14-0.15 at Step 140.
* Similar to the other line, it shows fluctuations, but appears to have slightly higher peaks and valleys.
### Key Observations
* Both models show a positive trend in "critic/rewards/mean" as the number of steps increases.
* The "qwen3\_1.7b\_dapo\_baseline" model appears to have slightly higher rewards towards the end of the plotted steps, but the difference is not substantial.
* Both lines exhibit significant fluctuations, suggesting variability in the rewards obtained at each step.
### Interpretation
The chart suggests that both models are learning and improving their performance over time, as indicated by the increasing "critic/rewards/mean". The "qwen3\_1.7b\_dapo\_baseline" model may be performing slightly better than the "qwen3\_1.7b\_grpo\_only\_old\_policy" model, but the difference is not significant. The fluctuations in the lines indicate that the learning process is not smooth and that there is variability in the rewards obtained at each step. This could be due to the stochastic nature of the environment or the learning algorithm.