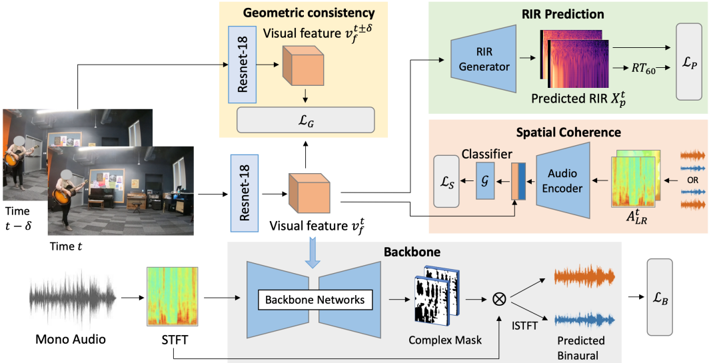
## Neural Network Architecture Diagram: Binaural Audio Prediction
### Overview
The image presents a diagram of a neural network architecture designed for binaural audio prediction. The architecture incorporates visual and audio inputs, processes them through several modules including ResNet-18, RIR prediction, and spatial coherence analysis, and ultimately predicts binaural audio output. The diagram illustrates the flow of data and the interactions between different components of the network.
### Components/Axes
* **Input:**
* Two images: "Time t - δ" and "Time t"
* Mono Audio
* **Modules:**
* ResNet-18 (used twice)
* Backbone Networks
* RIR Generator
* Classifier
* Audio Encoder
* **Outputs:**
* Predicted Binaural Audio
* **Loss Functions:**
* L<sub>G</sub> (Geometric consistency)
* L<sub>P</sub> (RIR Prediction)
* L<sub>S</sub> (Spatial Coherence)
* L<sub>B</sub> (Binaural Prediction)
* **Intermediate Representations:**
* Visual feature v<sub>f</sub><sup>t±δ</sup>
* Visual feature v<sub>f</sub><sup>t</sup>
* STFT (Short-Time Fourier Transform) of Mono Audio
* Predicted RIR X<sub>p</sub><sup>t</sup>
* A<sup>t</sup><sub>LR</sub>
* Complex Mask
### Detailed Analysis
1. **Input Branch (Visual):**
* Two images, captured at "Time t - δ" and "Time t", are fed into ResNet-18 networks.
* The ResNet-18 networks extract visual features v<sub>f</sub><sup>t±δ</sup> and v<sub>f</sub><sup>t</sup>.
* The visual features are used for geometric consistency, resulting in a loss L<sub>G</sub>.
2. **Input Branch (Audio):**
* Mono audio is transformed into its Short-Time Fourier Transform (STFT) representation.
* The STFT representation is fed into "Backbone Networks".
* The output of the "Backbone Networks" is a "Complex Mask".
3. **RIR Prediction Branch:**
* The visual feature v<sub>f</sub><sup>t±δ</sup> is fed into an "RIR Generator".
* The RIR Generator predicts the Room Impulse Response (RIR) X<sub>p</sub><sup>t</sup>.
* The predicted RIR is associated with a reverberation time RT<sub>60</sub>.
* The RIR prediction is associated with a loss L<sub>P</sub>.
4. **Spatial Coherence Branch:**
* The visual feature v<sub>f</sub><sup>t</sup> is fed into a "Classifier".
* The output of the classifier is combined with the output of an "Audio Encoder".
* The output of the Audio Encoder is A<sup>t</sup><sub>LR</sub>.
* The spatial coherence is associated with a loss L<sub>S</sub>.
5. **Backbone and Binaural Prediction:**
* The Complex Mask from the audio branch is combined (multiplied) with the output of the spatial coherence branch (A<sup>t</sup><sub>LR</sub>).
* The result is processed by an Inverse Short-Time Fourier Transform (ISTFT) to produce the "Predicted Binaural" audio.
* The binaural prediction is associated with a loss L<sub>B</sub>.
### Key Observations
* The architecture integrates visual and audio information to predict binaural audio.
* ResNet-18 is used to extract visual features from images at different time points.
* The RIR prediction branch aims to model the acoustic characteristics of the environment.
* The spatial coherence branch aims to capture the spatial relationships between audio sources.
* Loss functions are used to train the different modules of the network.
### Interpretation
The diagram illustrates a sophisticated approach to binaural audio prediction by leveraging both visual and audio cues. The use of ResNet-18 for visual feature extraction, combined with RIR prediction and spatial coherence analysis, suggests that the network attempts to model the acoustic environment and the spatial relationships between audio sources. The integration of these components allows the network to generate a more realistic and immersive binaural audio experience. The different loss functions (L<sub>G</sub>, L<sub>P</sub>, L<sub>S</sub>, L<sub>B</sub>) indicate that the network is trained to optimize geometric consistency, RIR prediction accuracy, spatial coherence, and binaural audio quality. The architecture is designed to learn the complex relationships between visual scenes and the corresponding binaural audio, enabling it to predict how sound would be perceived in a given environment.