\n
## Diagram: Audio-Visual Scene Analysis and Sound Event Localization
### Overview
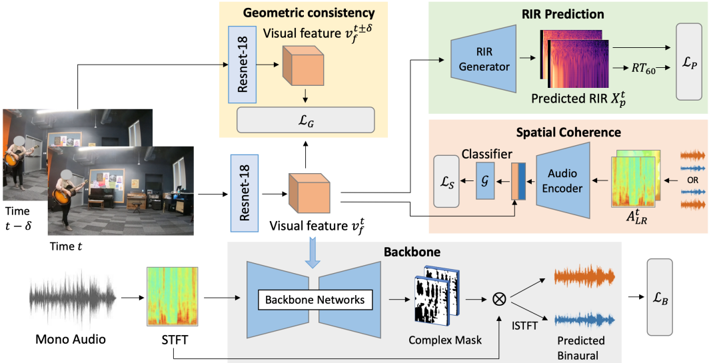
This diagram illustrates a system for predicting Room Impulse Responses (RIR) and localizing sound events within a visual scene. The system takes mono audio and visual input (frames at time t-δ and t) and processes them through several modules to estimate RIRs and predict binaural audio. The diagram is structured into three main processing branches: Geometric Consistency, RIR Prediction, and Spatial Coherence.
### Components/Axes
The diagram consists of the following key components:
* **Input:** Mono Audio, Visual Frames (Time t-δ, Time t)
* **Modules:** ResNet-18 (x2), RIR Generator, Classifier, Audio Encoder, Backbone Networks, ISTFT
* **Outputs:** Predicted RIR (X<sub>p</sub><sup>RT60</sup>), Predicted Binaural Audio
* **Loss Functions:** L<sub>C</sub>, L<sub>S</sub>, L<sub>B</sub>
* **Intermediate Representations:** Visual Feature (v<sub>t</sub><sup>δ</sup>, v<sub>t</sub>), STFT, Complex Mask, A<sub>LR</sub>
### Detailed Analysis or Content Details
**1. Visual Processing (Geometric Consistency & Spatial Coherence):**
* Two visual frames, labeled "Time t-δ" and "Time t", are input into separate ResNet-18 networks.
* The ResNet-18 networks extract "Visual Feature" representations, denoted as v<sub>t</sub><sup>δ</sup> and v<sub>t</sub> respectively. These are represented as cube-shaped blocks.
* The difference between these visual features (v<sub>t</sub><sup>δ</sup> and v<sub>t</sub>) is fed into a loss function L<sub>C</sub>, representing Geometric Consistency.
**2. RIR Prediction:**
* The visual feature v<sub>t</sub><sup>δ</sup> is input into an "RIR Generator".
* The RIR Generator outputs a "Predicted RIR" (X<sub>p</sub><sup>RT60</sup>), visualized as a spectrogram-like image with purple and red hues.
* The Predicted RIR is then passed through a block labeled "RT60" and then "p".
**3. Spatial Coherence:**
* The visual feature v<sub>t</sub> is input into a "Classifier".
* The Classifier outputs a representation labeled "L<sub>S</sub>" and "g".
* The visual feature v<sub>t</sub> is also input into an "Audio Encoder".
* The Audio Encoder outputs a representation labeled "A<sub>LR</sub>".