\n
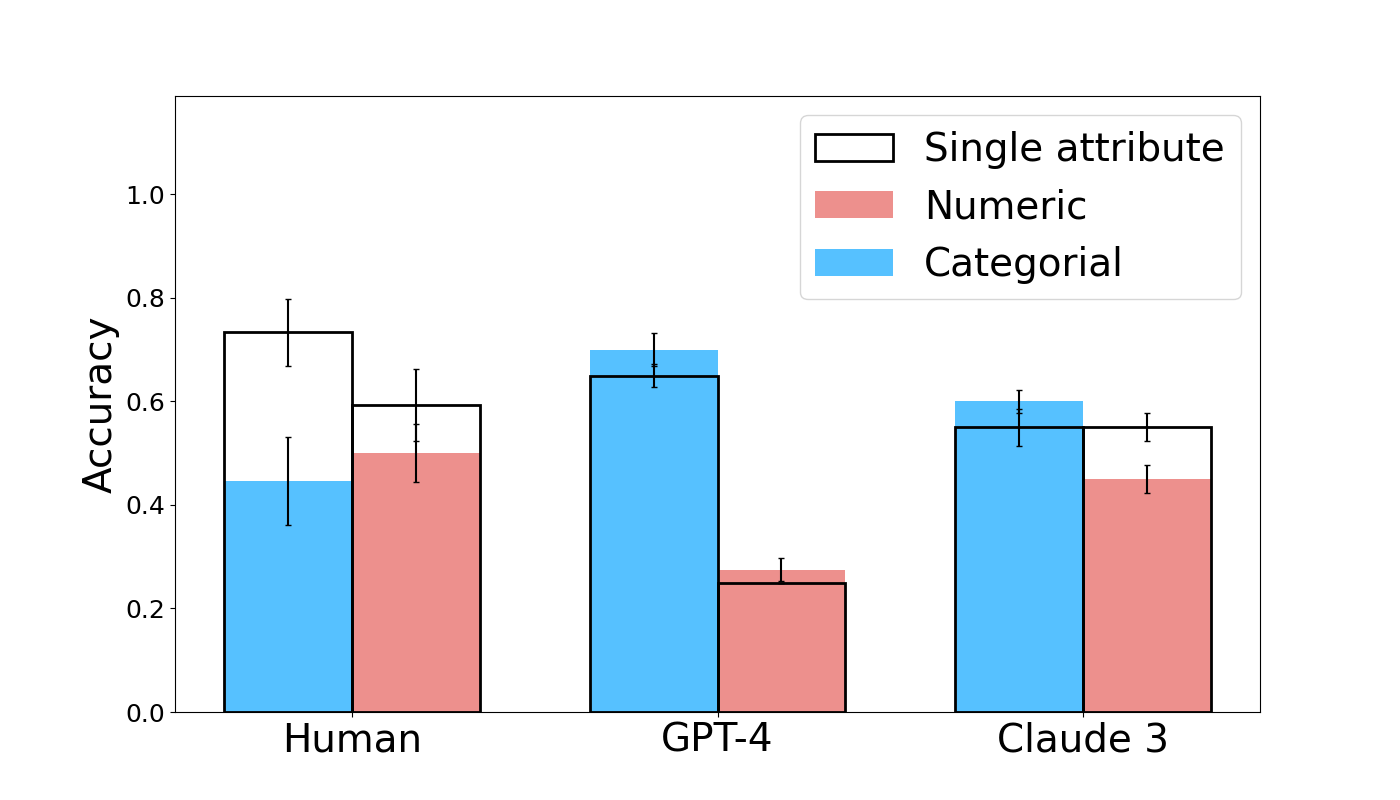
## Bar Chart: Accuracy Comparison of Human, GPT-4, and Claude 3
### Overview
This bar chart compares the accuracy of Human, GPT-4, and Claude 3 across three different data types: Single attribute, Numeric, and Categorical. Each data type is represented by a different color, and error bars indicate the variability in accuracy.
### Components/Axes
* **X-axis:** Represents the models being compared: Human, GPT-4, and Claude 3.
* **Y-axis:** Represents Accuracy, with a scale ranging from 0.0 to 1.0.
* **Legend:** Located in the top-right corner, defines the colors for each data type:
* Black outline: Single attribute
* Light Red: Numeric
* Light Blue: Categorical
### Detailed Analysis
The chart consists of three groups of bars, one for each model. Within each group, there are three bars representing the accuracy for each data type. Error bars are present on top of each bar, indicating the standard deviation or confidence interval.
**Human:**
* **Single attribute:** The bar is approximately 0.75 high, with error bars extending from roughly 0.65 to 0.85.
* **Numeric:** The bar is approximately 0.60 high, with error bars extending from roughly 0.50 to 0.70.
* **Categorical:** The bar is approximately 0.45 high, with error bars extending from roughly 0.35 to 0.55.
**GPT-4:**
* **Single attribute:** The bar is approximately 0.65 high, with error bars extending from roughly 0.55 to 0.75.
* **Numeric:** The bar is approximately 0.25 high, with error bars extending from roughly 0.15 to 0.35.
* **Categorical:** The bar is approximately 0.65 high, with error bars extending from roughly 0.55 to 0.75.
**Claude 3:**
* **Single attribute:** The bar is approximately 0.60 high, with error bars extending from roughly 0.50 to 0.70.
* **Numeric:** The bar is approximately 0.50 high, with error bars extending from roughly 0.40 to 0.60.
* **Categorical:** The bar is approximately 0.60 high, with error bars extending from roughly 0.50 to 0.70.
### Key Observations
* Humans generally achieve the highest accuracy for Numeric and Single attribute data types.
* GPT-4 performs poorly on Numeric data, with a significantly lower accuracy compared to other models and data types.
* GPT-4 and Claude 3 achieve similar accuracy on Categorical data, and both outperform Humans.
* The error bars suggest that the accuracy of Human performance on Categorical data has the highest variability.
### Interpretation
The data suggests that humans excel at tasks involving single attributes and numeric data, while GPT-4 and Claude 3 demonstrate stronger capabilities in handling categorical data. The poor performance of GPT-4 on numeric data is a notable outlier and warrants further investigation. The error bars indicate that human performance on categorical data is less consistent than that of the models. This could be due to subjective interpretation or inherent ambiguity in categorical data. The chart highlights the strengths and weaknesses of each model across different data types, suggesting that the optimal choice of model depends on the specific task at hand. The comparison suggests that while LLMs are improving, humans still maintain an edge in certain areas, particularly those requiring numerical reasoning.