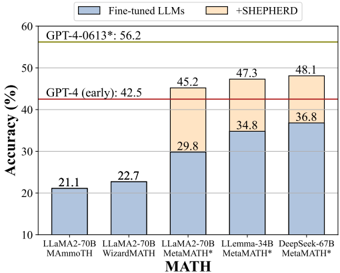
## Bar Chart: Math Problem Solving Accuracy
### Overview
This bar chart compares the accuracy of several Large Language Models (LLMs) on math problems. The chart shows the accuracy of "Fine-tuned LLMs" (blue bars) and the accuracy of the same LLMs when used with "+SHEPHERD" (beige bars). Horizontal red lines indicate the accuracy of GPT-4 (early) and GPT-4-0613. The x-axis represents different LLM models, and the y-axis represents accuracy in percentage.
### Components/Axes
* **X-axis:** LLM Models: LLaMA2-70B MATH, LLaMA2-70B WizardMATH, LLaMA2-70B MetaMATH*, LLemma-34B MetaMATH*, DeepSeek-67B MetaMATH*.
* **Y-axis:** Accuracy (%) - Scale ranges from 10 to 60, with increments of 10.
* **Legend:**
* Blue: Fine-tuned LLMs
* Beige: +SHEPHERD
* **Horizontal Lines:**
* GPT-4 (early): 42.5% (Red line)
* GPT-4-0613: 56.2% (Red line)
* **Title:** MATH (centered at the bottom of the chart)
### Detailed Analysis
The chart consists of five sets of stacked bars, each representing a different LLM.
1. **LLaMA2-70B MATH:**
* Fine-tuned LLMs (Blue): Approximately 21.1%
* +SHEPHERD (Beige): Not present.
2. **LLaMA2-70B WizardMATH:**
* Fine-tuned LLMs (Blue): Approximately 22.7%
* +SHEPHERD (Beige): Not present.
3. **LLaMA2-70B MetaMATH*:**
* Fine-tuned LLMs (Blue): Approximately 29.8%
* +SHEPHERD (Beige): Approximately 15.4% (45.2% total)
4. **LLemma-34B MetaMATH*:**
* Fine-tuned LLMs (Blue): Approximately 34.8%
* +SHEPHERD (Beige): Approximately 12.5% (47.3% total)
5. **DeepSeek-67B MetaMATH*:**
* Fine-tuned LLMs (Blue): Approximately 36.8%
* +SHEPHERD (Beige): Approximately 11.3% (48.1% total)
The red horizontal line for GPT-4 (early) is positioned at approximately 42.5% on the y-axis. The red horizontal line for GPT-4-0613 is positioned at approximately 56.2% on the y-axis.
### Key Observations
* The addition of "+SHEPHERD" consistently improves the accuracy of the LLMs.
* DeepSeek-67B MetaMATH* achieves the highest overall accuracy (48.1%) when combined with +SHEPHERD.
* LLaMA2-70B MATH and LLaMA2-70B WizardMATH have the lowest accuracy, even with +SHEPHERD.
* GPT-4-0613 outperforms all LLM/SHEPHERD combinations.
* GPT-4 (early) is outperformed by LLemma-34B MetaMATH* and DeepSeek-67B MetaMATH* with +SHEPHERD.
### Interpretation
The data suggests that "+SHEPHERD" is a valuable tool for enhancing the math problem-solving capabilities of LLMs. The consistent improvement across all models indicates that it provides a general benefit, likely by improving the reasoning or calculation steps. The performance of DeepSeek-67B MetaMATH* with +SHEPHERD is approaching that of GPT-4 (early), suggesting that fine-tuning and the use of tools like +SHEPHERD can significantly close the gap between open-source LLMs and state-of-the-art proprietary models. The relatively low performance of LLaMA2-70B MATH and WizardMATH suggests that these models may require more extensive fine-tuning or different architectural approaches to achieve comparable accuracy. The difference between the two GPT-4 versions (early vs. 0613) highlights the rapid progress in LLM development. The asterisk (*) after MetaMATH suggests a possible version or variant of the model.