## Bar Chart: Prediction Flip Rate Comparison for Llama-3-8B and Llama-3-70B
### Overview
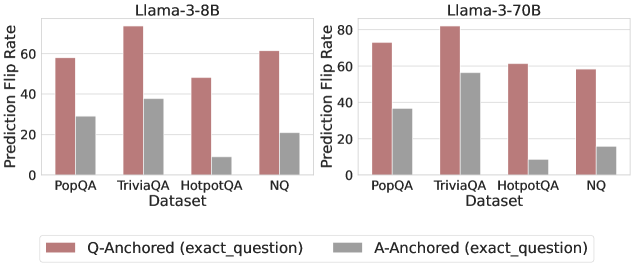
The image presents two bar charts comparing the prediction flip rates of two language models, Llama-3-8B and Llama-3-70B, across four different datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts compare "Q-Anchored" (exact question) and "A-Anchored" (exact question) methods, represented by different colored bars.
### Components/Axes
* **Titles:**
* Left Chart: Llama-3-8B
* Right Chart: Llama-3-70B
* **Y-axis:**
* Label: Prediction Flip Rate
* Scale: 0 to 80, with tick marks at intervals of 20.
* **X-axis:**
* Label: Dataset
* Categories: PopQA, TriviaQA, HotpotQA, NQ
* **Legend:** Located at the bottom of the chart.
* Rose/Pink Bar: Q-Anchored (exact\_question)
* Gray Bar: A-Anchored (exact\_question)
### Detailed Analysis
**Llama-3-8B (Left Chart):**
* **PopQA:**
* Q-Anchored: Approximately 58%
* A-Anchored: Approximately 30%
* **TriviaQA:**
* Q-Anchored: Approximately 78%
* A-Anchored: Approximately 38%
* **HotpotQA:**
* Q-Anchored: Approximately 48%
* A-Anchored: Approximately 10%
* **NQ:**
* Q-Anchored: Approximately 62%
* A-Anchored: Approximately 24%
**Llama-3-70B (Right Chart):**
* **PopQA:**
* Q-Anchored: Approximately 74%
* A-Anchored: Approximately 38%
* **TriviaQA:**
* Q-Anchored: Approximately 82%
* A-Anchored: Approximately 56%
* **HotpotQA:**
* Q-Anchored: Approximately 62%
* A-Anchored: Approximately 10%
* **NQ:**
* Q-Anchored: Approximately 58%
* A-Anchored: Approximately 16%
### Key Observations
* For both models and across all datasets, the Q-Anchored method consistently shows a higher prediction flip rate than the A-Anchored method.
* TriviaQA generally exhibits the highest prediction flip rates for both models and both anchoring methods.
* HotpotQA consistently shows the lowest A-Anchored prediction flip rates for both models.
* The Llama-3-70B model generally has higher prediction flip rates than the Llama-3-8B model, especially for the Q-Anchored method.
### Interpretation
The data suggests that using the exact question (Q-Anchored) leads to a higher likelihood of prediction flips compared to using the exact answer (A-Anchored). This could indicate that the models are more sensitive to variations or nuances in the question phrasing. The higher flip rates for TriviaQA might be due to the nature of trivia questions, which often have multiple possible correct answers or require specific knowledge. The Llama-3-70B model, being larger, appears to be more prone to prediction flips, possibly due to its increased complexity and capacity to memorize or overfit to specific question formats. The difference in performance between the two models highlights the impact of model size on prediction stability. The low A-Anchored flip rates for HotpotQA could indicate that the model is more robust when provided with the exact answer for this particular dataset.