\n
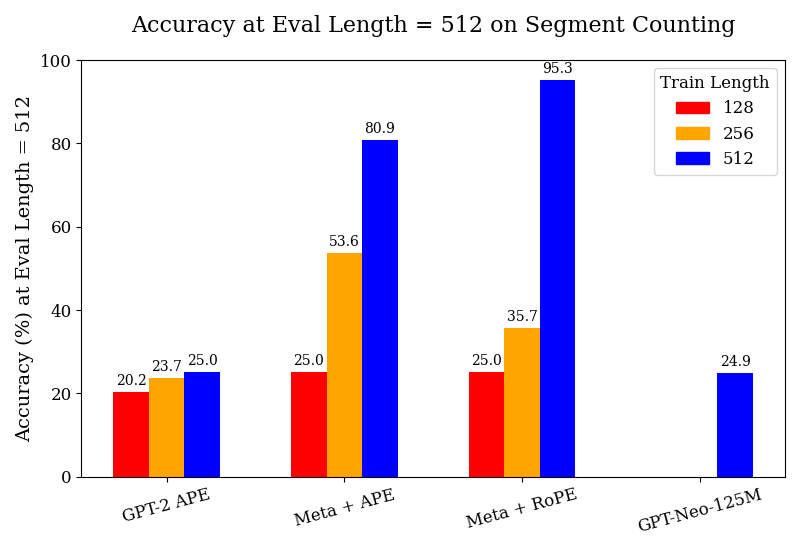
## Bar Chart: Accuracy at Eval Length = 512 on Segment Counting
### Overview
This is a grouped bar chart comparing the accuracy of four different language models or model configurations on a "Segment Counting" task. The evaluation is performed at a fixed sequence length of 512 tokens. The chart measures how model accuracy changes when trained on sequences of different lengths (128, 256, and 512 tokens).
### Components/Axes
* **Chart Title:** "Accuracy at Eval Length = 512 on Segment Counting"
* **Y-Axis:**
* **Label:** "Accuracy (%) at Eval Length = 512"
* **Scale:** Linear, from 0 to 100 in increments of 20.
* **X-Axis:** Lists four model configurations:
1. GPT-2 APE
2. Meta + APE
3. Meta + RoPE
4. GPT-Neo-125M
* **Legend:** Located in the top-right corner. It defines the "Train Length" for the colored bars:
* **Red Bar:** Train Length = 128
* **Orange Bar:** Train Length = 256
* **Blue Bar:** Train Length = 512
### Detailed Analysis
The chart presents accuracy percentages for each model across available training lengths. The data points, extracted by matching bar color to the legend, are as follows:
**1. GPT-2 APE**
* **Trend:** Shows a slight, monotonic increase in accuracy as training length increases.
* **Data Points:**
* Train Length 128 (Red): **20.2%**
* Train Length 256 (Orange): **23.7%**
* Train Length 512 (Blue): **25.0%**
**2. Meta + APE**
* **Trend:** Shows a strong, monotonic increase in accuracy with longer training lengths. The jump from 256 to 512 is substantial.
* **Data Points:**
* Train Length 128 (Red): **25.0%**
* Train Length 256 (Orange): **53.6%**
* Train Length 512 (Blue): **80.9%**
**3. Meta + RoPE**
* **Trend:** Shows the most dramatic increase. Accuracy is flat between train lengths 128 and 256, then surges dramatically at 512.
* **Data Points:**
* Train Length 128 (Red): **25.0%**
* Train Length 256 (Orange): **35.7%**
* Train Length 512 (Blue): **95.3%**
**4. GPT-Neo-125M**
* **Trend:** Only one data point is provided. No trend can be established.
* **Data Point:**
* Train Length 512 (Blue): **24.9%**
### Key Observations
1. **Scaling with Training Length:** For the "Meta" architectures (both APE and RoPE), training on longer sequences (512) yields dramatically higher accuracy on the 512-length evaluation task compared to training on shorter sequences (128 or 256). This effect is much less pronounced for GPT-2 APE.
2. **Architecture Performance:** At the matched train/eval length of 512, the "Meta + RoPE" configuration achieves the highest accuracy by a significant margin (95.3%), followed by "Meta + APE" (80.9%). GPT-2 APE and GPT-Neo-125M perform similarly poorly at this length (~25%).
3. **Baseline Performance:** When trained on the shortest length (128), all three models with available data (GPT-2 APE, Meta + APE, Meta + RoPE) cluster around 20-25% accuracy, suggesting a common baseline difficulty for the task with limited training context.
4. **Missing Data:** GPT-Neo-125M lacks data for train lengths 128 and 256, preventing a full comparison of its scaling behavior.
### Interpretation
The data strongly suggests that the "Meta" model architectures possess a superior ability to leverage longer training sequences to solve the segment counting task, especially when evaluated at that same length. The near-perfect accuracy (95.3%) of "Meta + RoPE" at train length 512 indicates that this combination (Meta architecture with Rotary Position Embeddings) is highly effective for this specific length-generalization challenge.
The stark contrast between the Meta models and the baselines (GPT-2, GPT-Neo) implies that architectural innovations beyond the base transformer are critical for tasks requiring precise reasoning over long contexts. The minimal improvement of GPT-2 APE with longer training suggests it may hit a performance ceiling or lack the mechanisms to effectively use the additional context. The single, low data point for GPT-Neo-125M positions it as a weaker baseline for this task at the 512-length scale.
In summary, the chart demonstrates that for segment counting at length 512, **model architecture and the alignment of training length with evaluation length are the dominant factors determining success**, with the Meta + RoPE configuration being the clear winner.